
تجزیه و تحلیل توصیفی در برنامه نویسی R
در آمار توصیفی در زبان برنامه نویسی R داده های خود را با کمک روش های مختلف نمایندگی با استفاده از نمودارها، نمودارها، جداول، فایل های اکسل و غیره توصیف می کنیم. تا به راحتی قابل درک باشد.
بیشتر اوقات بر روی مجموعه داده های کوچک انجام می شود و این تحلیل به ما کمک زیادی می کند تا برخی روندهای آینده را بر اساس یافته های فعلی پیش بینی کنیم. برخی از معیارهایی که برای توصیف یک مجموعه داده استفاده میشوند، معیارهای گرایش مرکزی و معیارهای تغییرپذیری یا پراکندگی هستند.
فرآیند آمار توصیفی در R
- معیار گرایش مرکزی
- اندازه گیری تغییرپذیری
اندازه گیری گرایش مرکزی
کل مجموعه داده ها را با یک مقدار نشان می دهد. موقعیت نقاط مرکزی را به ما می دهد. سه معیار اصلی برای گرایش مرکزی وجود دارد:
- میانگین / Mean
- حالت / Mode
- میانه / Median
اندازه گیری تغییرپذیری
در آمار توصیفی در R اندازه گیری تنوع به عنوان پراکندگی داده ها یا میزان توزیع خوب داده های ما شناخته می شود. رایج ترین معیارهای تغییرپذیری عبارتند از:
- محدوده / Range
- واریانس / Variance
- انحراف معیار / Standard deviation
نیاز به آمار توصیفی در R
تجزیه و تحلیل توصیفی به ما کمک می کند تا داده های خود را درک کنیم و بخش بسیار مهمی از یادگیری ماشین است. این به این دلیل است که یادگیری ماشینی تماماً در مورد پیشبینی است. از سوی دیگر، آمار همه چیز در مورد نتیجه گیری از داده ها است، که یک گام اولیه ضروری برای یادگیری ماشین است. بیایید این تحلیل توصیفی را در R انجام دهیم.
تحلیل توصیفی در R
تجزیه و تحلیل توصیفی شامل توصیف ساده داده ها با استفاده از برخی آمار خلاصه و گرافیک است. در اینجا نحوه محاسبه آمار خلاصه با استفاده از نرم افزار R را شرح خواهیم داد.
داده های خود را به R وارد کنید:
قبل از انجام هر محاسباتی، اول از همه، باید دادههای خود را آماده کنیم، دادههای خود را در فایلهای txt. یا csv. خارجی ذخیره کنیم و بهترین روش ذخیره فایل در فهرست فعلی است. پس از آن وارد کردن، داده های شما در R به صورت زیر است:
# R program to illustrate # Descriptive Analysis # Import the data using read.csv() myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F) # Print the first 6 rows print(head(myData))
خروجی :
Product Age Gender Education MaritalStatus Usage Fitness Income Miles 1 TM195 18 Male 14 Single 3 4 29562 112 2 TM195 19 Male 15 Single 2 3 31836 75 3 TM195 19 Female 14 Partnered 4 3 30699 66 4 TM195 19 Male 12 Single 3 3 32973 85 5 TM195 20 Male 13 Partnered 4 2 35247 47 6 TM195 20 Female 14 Partnered 3 3 32973 66
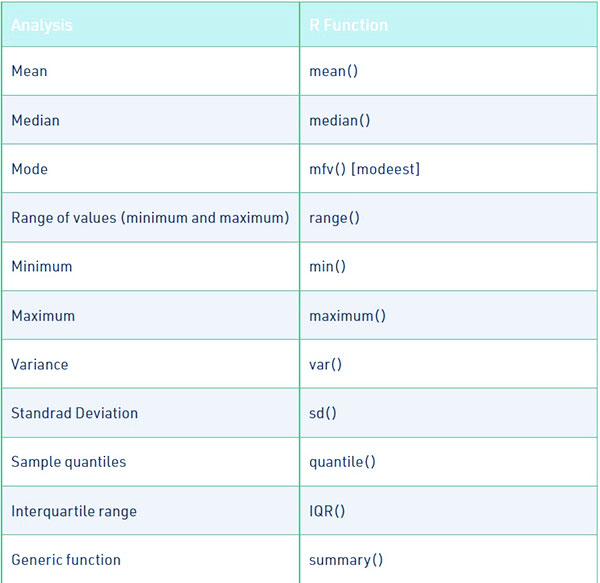
توابع R برای محاسبه تحلیل توصیفی:
هیستوگرام توزیع سنی
library(ggplot2) ggplot(myData, aes(x = Age)) + geom_histogram(binwidth = 2, fill = "blue", color = "red", alpha = 0.8) + labs(title = "Age Distribution", x = "Age", y = "Frequency")
خروجی :
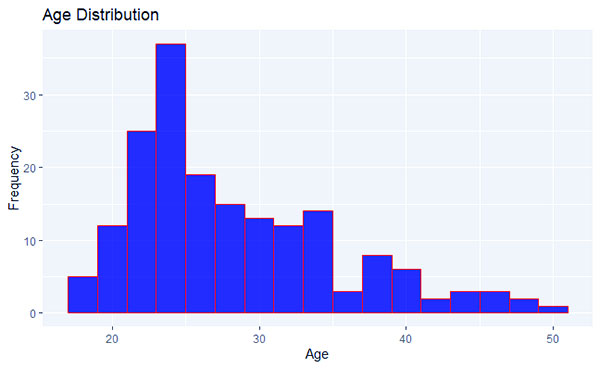
کتابخانه ggplot2 برای ایجاد یک هیستوگرام از متغیر “Age” از مجموعه داده “myData”. سطل های هیستوگرام 2 عرض دارند و میله ها با رنگ آبی با حاشیه خاکستری روشن پر شده اند. تجسم حاصل، توزیع سنی را در مجموعه داده نشان می دهد.
Boxplot بر اساس جنسیت
ggplot(myData, aes(x = Gender, y = Miles, fill = Gender)) + geom_boxplot() + labs(title = "Miles Distribution by Gender", x = "Gender", y = "Miles") + theme_minimal()
خروجی :
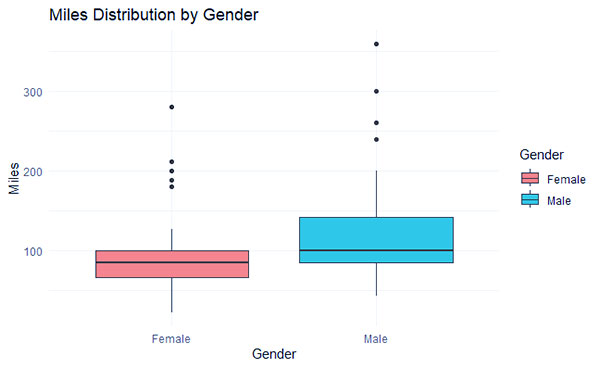
ما یک نمودار Boxplot ایجاد می کنیم که توزیع «Miles» را به تصویر می کشد، که بر اساس «جنسیت» از مجموعه داده «myData» تقسیم شده است. هر Boxplot نمودار محدوده بین ربعی (IQR) مایل ها را برای هر جنسیت نشان می دهد. این طرح با عنوان «توزیع مایل بر اساس جنسیت» با «جنسیت» در محور x و «مایل» در محور y نامگذاری شده است. طرح با موضوعی مینیمال طراحی شده است.
نمودار میله ای سطوح آموزش
ggplot(myData, aes(x = factor(Education), fill = factor(Education))) + geom_bar() + labs(title = "Education Distribution", x = "Education Level", y = "Count") + theme_minimal()
خروجی :
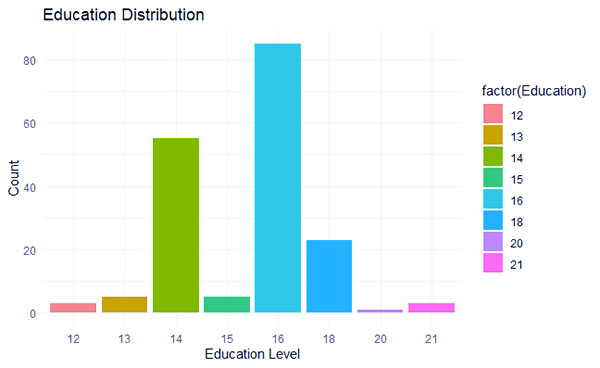
ما یک نمودار میله ای ایجاد می کنیم که توزیع سطوح “آموزش” را از مجموعه داده “myData” نشان می دهد. هر نوار نشان دهنده تعداد مشاهدات برای هر سطح تحصیلی است. این نمودار با عنوان «توزیع آموزش» با «سطح آموزش» در محور x و «شمارش» در محور y است. تجسم یک موضوع حداقلی را برای ارائه تمیز و ساده اتخاذ می کند.
میانگین
مجموع مشاهدات تقسیم بر تعداد کل مشاهدات است. همچنین به عنوان میانگین تعریف می شود که مجموع تقسیم بر تعداد است.
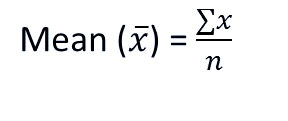
که در آن n = تعداد اصطلاحات
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Compute the mean value
mean = mean(myData$Age)
print(mean)
خروجی :
[1] 28.78889
میانه
این مقدار وسط مجموعه داده است. داده ها را به دو نیمه تقسیم می کند. اگر تعداد عناصر در مجموعه داده فرد باشد، عنصر مرکزی میانه است و اگر زوج باشد، میانه میانگین دو عنصر مرکزی خواهد بود.
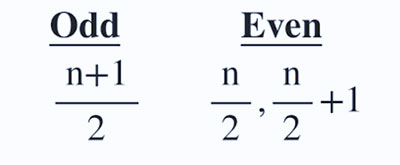
که در آن n = تعداد اصطلاحات
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Compute the median value
median = median(myData$Age)
print(median)
خروجی :
[1] 26
حالت
مقداری است که بیشترین فراوانی را در مجموعه داده داده شده دارد. اگر فرکانس تمام نقاط داده یکسان باشد ممکن است مجموعه داده حالت نداشته باشد. همچنین اگر با دو یا چند نقطه داده با فرکانس یکسان مواجه شویم، می توانیم بیش از یک حالت داشته باشیم.
# R program to illustrate
# Descriptive Analysis
# Import the library
library(modeest)
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Compute the mode value
mode = mfv(myData$Age)
print(mode)
خروجی :
[1] 25
محدوده
محدوده تفاوت بین بزرگترین و کوچکترین نقطه داده در مجموعه داده ما را توصیف می کند. هرچه دامنه بزرگتر باشد، انتشار داده ها بیشتر است و بالعکس.
محدوده = بزرگترین مقدار داده – کوچکترین مقدار داده
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Calculate the maximum
max = max(myData$Age)
# Calculate the minimum
min = min(myData$Age)
# Calculate the range
range = max - min
cat("Range is:\n")
print(range)
# Alternate method to get min and max
r = range(myData$Age)
print(r)
خروجی :
Range is: [1] 32 [1] 18 50
واریانس
به عنوان یک انحراف مجذور میانگین از میانگین تعریف می شود. با یافتن تفاوت بین هر نقطه داده و میانگین که به عنوان میانگین نیز شناخته می شود، آنها را مربع می کنیم، همه آنها را جمع می کنیم و سپس بر تعداد نقاط داده موجود در مجموعه داده ما تقسیم می کنیم.
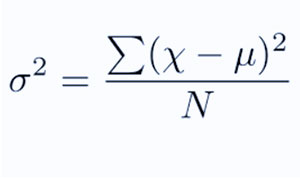
N = تعداد اصطلاحات
u = متوسط
# R program to illustrate # Descriptive Analysis # Import the data using read.csv() myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F) # Calculating variance variance = var(myData$Age) print(variance)
خروجی :
[1] 48.21217
انحراف معیار
به عنوان جذر واریانس تعریف می شود. با یافتن میانگین محاسبه می شود، سپس هر عدد را از میانگین که به عنوان میانگین نیز شناخته می شود، کم کرده و حاصل را مربع می کنیم. جمع کردن تمام مقادیر و سپس تقسیم بر تعداد عبارت ها به دنبال جذر.
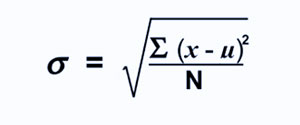
N = تعداد اصطلاحات
u = متوسط
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F)
# Calculating Standard deviation
std = sd(myData$Age)
print(std)
خروجی :
[1] 6.943498
برخی تابع R بیشتر در آمار توصیفی در R استفاده می شود
Quartiles
Quartiles نوعی quantile است. Quartile اول (Q1)، به عنوان عدد وسط بین کوچکترین عدد و میانه مجموعه داده تعریف می شود، Quartile دوم (Q2) – میانه مجموعه داده داده شده در حالی که Quartile سوم (Q3)، وسط است. عدد بین میانه و بزرگترین مقدار مجموعه داده.
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F)
# Calculating Quartiles
quartiles = quantile(myData$Age)
print(quartiles)
خروجی :
0% 25% 50% 75% 100% 18 24 26 33 50
محدوده Interquartile
محدوده Interquartile (IQR) که به آن 50 درصد میانی یا میانی نیز می گویند یا از نظر فنی H-spread، تفاوت بین quartile سوم (Q3) و quartile اول (Q1) است. مرکز توزیع را پوشش می دهد و 50 درصد مشاهدات را شامل می شود.
IQR = Q3 – Q1
# R program to illustrate # Descriptive Analysis # Import the data using read.csv() myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F) # Calculating IQR IQR = IQR(myData$Age) print(IQR)
خروجی :
[1] 9
تابع summary() در R
تابع summary() می تواند برای نمایش چند خلاصه آماری از یک متغیر یا کل قاب داده استفاده شود.
خلاصه یک متغیر منفرد:
# R program to illustrate # Descriptive Analysis # Import the data using read.csv() myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F) # Calculating summary summary = summary(myData$Age) print(summary)
خروجی :
Min. 1st Qu. Median Mean 3rd Qu. Max. 18.00 24.00 26.00 28.79 33.00 50.00
خلاصه چارچوب داده / data frame
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Calculating summary
summary = summary(myData)
print(summary)
خروجی :
Product Age Gender Education Length:180 Min. :18.00 Length:180 Min. :12.00 Class :character 1st Qu.:24.00 Class :character 1st Qu.:14.00 Mode :character Median :26.00 Mode :character Median :16.00 Mean :28.79 Mean :15.57 3rd Qu.:33.00 3rd Qu.:16.00 Max. :50.00 Max. :21.00 MaritalStatus Usage Fitness Income Miles Length:180 Min. :2.000 Min. :1.000 Min. : 29562 Min. : 21.0 Class :character 1st Qu.:3.000 1st Qu.:3.000 1st Qu.: 44059 1st Qu.: 66.0 Mode :character Median :3.000 Median :3.000 Median : 50597 Median : 94.0 Mean :3.456 Mean :3.311 Mean : 53720 Mean :103.2 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.: 58668 3rd Qu.:114.8 Max. :7.000 Max. :5.000 Max. :104581 Max. :360.0
برای خرید لایسنس نرم افزار Tableau ، میتوانید از خدمات ما استفاده نموده و درخواست خود را از طریق فرم زیر ثبت نمایید.



{kind=link}
بدون دیدگاه