
معرفی توابع رشته string functions در تبلو
این مقاله به معرفی توابع رشته و کاربرد آنها در Tableau می پردازد. همچنین نحوه ایجاد یک محاسبه رشته را با استفاده از یک مثال نشان می دهد.
چرا از توابع رشته / String استفاده کنیم؟
توابع رشته ای به شما امکان می دهند داده های رشته ای (یعنی داده های ساخته شده از متن) را دستکاری کنید. Tableau از کتابخانه کنونی International Components for Unicode (ICU) هنگام مقایسه رشته ها استفاده می کند. نحوه مرتبسازی و مقایسه رشتهها هم بر اساس زبان و هم بر اساس محلی است، و این امکان وجود دارد که vizzes با بهروزرسانی مداوم ICU برای پشتیبانی بهتر زبان، تغییر کند.
برای مثال، ممکن است فیلدی داشته باشید که شامل نام و نام خانوادگی همه مشتریان شما باشد. یکی از اعضا ممکن است این باشد: جین جانسون. میتوانید با استفاده از یک تابع رشته، نامهای خانوادگی همه مشتریان خود را به یک فیلد جدید بکشید.
محاسبه ممکن است چیزی شبیه به این باشد:
SPLIT([Customer Name], ' ', 2)
بنابراین
SPLIT('Jane Johnson' , ' ', 2) = ‘Johnson’.
توابع رشته ای موجود در Tableau
ASCII
| Syntax | ASCII(string) |
| Output | Number |
| تعریف | کد ASCII اولین کاراکتر a را برمی گرداند <string>. |
| مثال |
ASCII('A') = 65
|
| یادداشت | این برعکس تابع CHAR است. |
CHAR
| Syntax | CHAR(number) |
| Output | String |
| تعریف | کاراکتر کدگذاری شده توسط کد ASCII را برمی گرداند <number>. |
| مثال |
CHAR(65) = 'A' |
| یادداشت | این معکوس تابع ASCII است. |
CONTAINS
| Syntax | CONTAINS(string, substring) |
| Output | Boolean |
| تعریف | اگر رشته داده شده حاوی زیررشته مشخص شده باشد، مقدار true را برمی گرداند. |
| مثال |
CONTAINS("Calculation", "alcu") = true
|
| یادداشت | همچنین تابع منطقی IN و همچنین RegEx پشتیبانی شده را در مستند توابع اضافی ببینید. |
ENDSWITH
| Syntax | ENDSWITH(string, substring) |
| Output | Boolean |
| تعریف | اگر رشته داده شده با رشته فرعی مشخص شده به پایان برسد، مقدار true را برمی گرداند. فضاهای سفید بعدی نادیده گرفته می شوند. |
| مثال |
ENDSWITH("Tableau", "leau") = true
|
| یادداشت | همچنین RegEx پشتیبانی شده را در مستند توابع اضافی ببینید. |
FIND
| Syntax | FIND(string, substring, [start]) |
| Output | Number |
| تعریف | موقعیت شاخص رشته فرعی در رشته یا 0 را در صورت یافت نشدن رشته فرعی برمی گرداند. اولین کاراکتر در رشته موقعیت 1 است.
اگر آرگومان عددی اختیاری شروع اضافه شود، تابع هر نمونه از رشته فرعی را که قبل از موقعیت شروع ظاهر می شود نادیده می گیرد. |
| مثال |
FIND("Calculation", "alcu") = 2
FIND("Calculation", "Computer") = 0
FIND("Calculation", "a", 3) = 7
FIND("Calculation", "a", 2) = 2
FIND("Calculation", "a", 8) = 0
|
| یادداشت | همچنین RegEx پشتیبانی شده را در مستند توابع اضافی ببینید. |
FINDNTH
| Syntax | FINDNTH(string, substring, occurrence) |
| Output | Number |
| تعریف | موقعیت nمین وقوع زیررشته را در رشته مشخص شده برمیگرداند، جایی که n با آرگومان وقوع تعریف میشود. |
| مثال |
FINDNTH("Calculation", "a", 2) = 7
|
| یادداشت | FINDNTH برای همه منابع داده در دسترس نیست.
همچنین RegEx پشتیبانی شده را در مستند توابع اضافی ببینید. |
LEFT
| Syntax | LEFT(string, number) |
| Output | String |
| تعریف | سمت چپ ترین <number> کاراکترهای رشته را برمی گرداند. |
| مثال |
LEFT("Matador", 4) = "Mata"
|
| یادداشت | همچنین به MID و RIGHT مراجعه کنید. |
LEN
| Syntax | LEN(string) |
| Output | Number |
| تعریف | طول رشته را برمی گرداند. |
| مثال |
LEN("Matador") = 7
|
| یادداشت | نباید با spatial function LENGTH اشتباه گرفته شود. |
LOWER
| Syntax | LOWER(string) |
| Output | String |
| تعریف | <string> ارائه شده را با تمام نویسههای کوچک برمیگرداند. |
| مثال |
LOWER("ProductVersion") = "productversion"
|
| یادداشت | همچنین به UPPER و PROPER مراجعه کنید. |
LTRIM
| Syntax | LTRIM(string) |
| Output | String |
| تعریف | <string> ارائه شده را با حذف تمام فاصله های اصلی باز می گرداند. |
| مثال |
LTRIM(" Matador ") = "Matador "
|
| یادداشت | RTRIM را نیز ببینید. |
MAX
| Syntax | MAX(expression) or MAX(expr1, expr2) |
| Output | نوع داده مشابه آرگومان یا NULL اگر هر بخشی از آرگومان تهی باشد. |
| تعریف | حداکثر دو آرگومان را برمیگرداند که باید از یک نوع داده باشند.
MAX همچنین میتواند در یک فیلد بهعنوان تجمیع اعمال شود. |
| مثال |
MAX(4,7) = 7 MAX(#3/25/1986#, #2/20/2021#) = #2/20/2021# MAX([Name]) = "Zander" |
| یادداشت | برای رشته هاMAX معمولاً مقداری است که به ترتیب حروف الفبا در آخر قرار می گیرد.
برای منابع داده پایگاه داده، مقدار رشته MAX در ترتیب مرتب سازی که توسط پایگاه داده برای آن ستون تعریف شده است، بالاترین مقدار است. تاریخ ها به صورت تجمیع به عنوان مقایسه MIN را نیز ببینید. |
MID
| Syntax | (MID(string, start, [length]) |
| Output | String |
| تعریف | رشتهای را برمیگرداند که از موقعیت شروع مشخص شده شروع میشود. اولین کاراکتر در رشته موقعیت 1 است.
اگر طول آرگومان عددی اختیاری اضافه شود، رشته برگشتی فقط آن تعداد کاراکتر را شامل میشود. |
| مثال |
MID("Calculation", 2) = "alculation"
MID("Calculation", 2, 5) ="alcul"
|
| یادداشت | همچنین RegEx پشتیبانی شده را در مستند توابع اضافی ببینید. |
MIN
| Syntax | MIN(expression) or MIN(expr1, expr2) |
| Output | نوع داده مشابه آرگومان یا NULL اگر هر بخشی از آرگومان تهی باشد. |
| تعریف | حداقل دو آرگومان را برمیگرداند که باید از یک نوع داده باشند.
MIN همچنین میتواند در یک فیلد بهعنوان تجمیع اعمال شود. |
| مثال |
MIN(4,7) = 4 MIN(#3/25/1986#, #2/20/2021#) = #3/25/1986# MIN([Name]) = "Abebi" |
| یادداشت | برای رشته ها MIN معمولاً مقداری است که به ترتیب حروف الفبا اول است.برای منابع داده پایگاه داده، مقدار رشته MIN در ترتیب مرتبسازی که پایگاه داده برای آن ستون تعریف میکند، کمترین مقدار است.تاریخها برای تاریخها، MIN اولین تاریخ است. اگر MIN یک تجمیع باشد، نتیجه سلسله مراتب تاریخ نخواهد داشت. اگر MIN یک مقایسه باشد، نتیجه سلسله مراتب تاریخ را حفظ خواهد کرد. به صورت تجمیع به عنوان مقایسه MAX را نیز ببینید. |
PROPER
| Syntax | PROPER(string) |
| Output | String |
| تعریف | <رشته> ارائه شده را برمیگرداند که حرف اول هر کلمه بزرگ و حروف باقی مانده با حروف کوچک باشد. |
| مثال |
PROPER("PRODUCT name") = "Product Name"
PROPER("darcy-mae") = "Darcy-Mae"
|
| یادداشت | فاصله ها و نویسه های غیرالفبایی مانند علائم نگارشی به عنوان جداکننده در نظر گرفته می شوند.
همچنین به LOWER و UPPER مراجعه کنید. |
| محدودیت های پایگاه داده | PROPER فقط برای برخی از فایل های مسطح و به صورت extract در دسترس است. اگر نیاز به استفاده از PROPER در منبع داده ای دارید که در غیر این صورت از آن پشتیبانی نمی کند، استفاده از استخراج را در نظر بگیرید. |
REPLACE
| Syntax | REPLACE(string, substring, replacement |
| Output | String |
| تعریف | <string> را <substring> را جستجو میکند و آن را با <replacement> جایگزین میکند. اگر <substring> پیدا نشد، رشته تغییر نمیکند. |
| مثال |
REPLACE("Version 3.8", "3.8", "4x") = "Version 4x"
|
| یادداشت | همچنین REGEXP_REPLACE را در مستند توابع اضافی ببینید. |
RIGHT
| Syntax | RIGHT(string, number) |
| Output | String |
| تعریف | سمت راست ترین <number> کاراکترهای رشته را برمیگرداند. |
| مثال |
RIGHT("Calculation", 4) = "tion"
|
| یادداشت | همچنین به LEFT و MID مراجعه کنید. |
RTRIM
| Syntax | RTRIM(string) |
| Output | String |
| تعریف | <string> ارائه شده را با حذف تمام فاصلههای انتهایی برمیگرداند. |
| مثال |
RTRIM(" Calculation ") = " Calculation"
|
| یادداشت | همچنین به LTRIM و TRIM مراجعه کنید. |
SPACE
| Syntax | SPACE(number) |
| Output | رشته (به طور خاص، فقط فاصله) |
| تعریف | رشته ای را برمی گرداند که از تعداد مشخصی فاصله های تکراری تشکیل شده است. |
| مثال |
SPACE(2) = " " |
SPLIT
| Syntax | SPLIT(string, delimiter, token number) |
| Output | String |
| تعریف | یک رشته فرعی از یک رشته را با استفاده از یک کاراکتر جداکننده برای تقسیم رشته به دنباله ای از نشانه ها برمی گرداند. |
| مثال |
SPLIT ("a-b-c-d", "-", 2) = "b"
SPLIT ("a|b|c|d", "|", -2) = "c"
|
| یادداشت | رشته به عنوان یک دنباله متناوب از جداکننده ها و نشانه ها تفسیر می شود. بنابراین برای رشته abc-defgh-i-jkl، که در آن کاراکتر جداکننده ‘-‘ است، نشانهها (1) abc، (2) defgh، (3) i و (4) jlk هستند.
SPLIT رمز مربوط به شماره رمز را برمیگرداند. هنگامی که شماره رمز مثبت است، نشانه ها از انتهای سمت چپ رشته شمارش می شوند. هنگامی که شماره نشانه منفی است، توکن ها از سمت راست شمارش می شوند همچنین RegEx پشتیبانی شده را در مستند توابع اضافی ببینید. |
| محدودیت های پایگاه داده | دستورات تقسیم و تقسیم سفارشی برای انواع منابع داده زیر در دسترس هستند: استخراج داده های Tableau، Microsoft Excel، Text File، فایل PDF، Salesforce، OData، Microsoft Azure Market Place، Google Analytics، Vertica، Oracle، MySQL، PostgreSQL، Teradata، Amazon Redshift، Aster Data، Google Big Query، Cloudera Hadoop Hive، Hortonworks Hive و Microsoft SQL Server.
برخی از منابع داده محدودیت هایی را برای تقسیم رشته ها اعمال می کنند. محدودیتهای عملکرد SPLIT را بعداً در این مبحث ببینید. |
STARTSWITH
| Syntax | STARTSWITH(string, substring) |
| Output | Boolean |
| تعریف | اگر رشته با رشته فرعی شروع شود true برمیگرداند. فضاهای سفید پیشرو نادیده گرفته می شوند. |
| مثال |
STARTSWITH("Matador, "Ma") = TRUE
|
| یادداشت | همچنین CONTINS و REGEX پشتیبانی شده را در مستند توابع اضافی ببینید. |
TRIM
| Syntax | TRIM(string) |
| Output | String |
| تعریف | <رشته> ارائه شده را با حذف فاصله های اصلی و انتهایی برمی گرداند. |
| مثال |
TRIM(" Calculation ") = "Calculation"
|
| یادداشت | همچنین به LTRIM و RTRIM مراجعه کنید. |
UPPER
| Syntax | UPPER(string) |
| Output | String |
| تعریف | <string> ارائه شده را با تمام نویسههای بزرگ برمیگرداند. |
| مثال |
UPPER("Calculation") = "CALCULATION"
|
| یادداشت | همچنین به PROPER و LOWER مراجعه کنید. |
یک محاسبه رشته ایجاد کنید
برای یادگیری نحوه ایجاد یک محاسبه رشته، مراحل زیر را دنبال کنید.
- در Tableau Desktop، به منبع داده ذخیره شده Sample – Superstore که با Tableau ارائه می شود، متصل شوید.
- به یک کاربرگ بروید.
- از پنجره Data، در قسمت Dimensions، شناسه سفارش را به قفسه ردیفها بکشید.
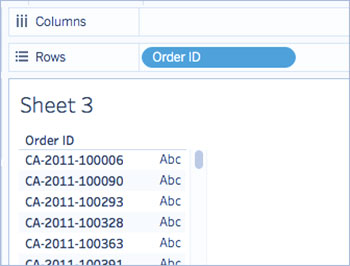
توجه داشته باشید که هر شناسه سفارش حاوی مقادیری برای کشور (به عنوان مثال، CA و ایالات متحده)، سال (2011) و شماره سفارش (100006) است. برای این مثال، شما یک محاسبه برای بیرون کشیدن فقط شماره سفارش از فیلد ایجاد می کنید.
- تجزیه و تحلیل > ایجاد فیلد محاسبه شده را انتخاب کنید.
- در ویرایشگر محاسباتی که باز می شود، موارد زیر را انجام دهید:
- فیلد محاسبه شده Order ID Numbers را نامگذاری کنید.
- فرمول زیر را وارد کنید:
RIGHT([Order ID], 6)
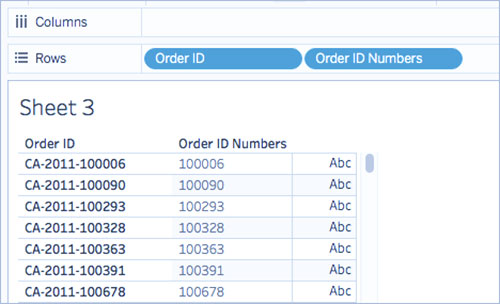
این فرمول ارقام مشخص شده (6) را از سمت راست رشته می گیرد و آنها را به یک فیلد جدید می کشد.
بنابراین، RIGHT(‘CA-2011-100006’ , 6) = ‘100006’.
- پس از اتمام، روی OK کلیک کنید.
فیلد محاسبه شده جدید در قسمت Dimensions در قسمت Data ظاهر می شود. درست مانند سایر زمینه های خود، می توانید از آن در یک یا چند تصویرسازی استفاده کنید.
6. از پنجره Data، Order ID Numbers را به قفسه Rows بکشید. آن را در سمت راست شناسه سفارش قرار دهید.
به تفاوت فیلدها توجه کنید.
محدودیتهای SPLIT بر اساس منبع داده
برخی از منابع داده محدودیت هایی را برای تقسیم رشته اعمال می کنند. جدول زیر نشان می دهد که کدام منابع داده از اعداد رمز منفی (تقسیم از سمت راست) پشتیبانی می کنند و آیا محدودیتی در تعداد مجاز تقسیم به ازای هر منبع داده وجود دارد.
یک تابع SPLIT که یک شماره رمز منفی را مشخص می کند و با سایر منابع داده قانونی است، این خطا را با این منابع داده برمی گرداند: “تقسیم از راست توسط منبع داده پشتیبانی نمی شود.”
| منبع داده | محدودیت های Left/Right | حداکثر تعداد تقسیم | محدودیت های نسخه |
| Tableau Data Extract | هر دو | بی نهایت | |
| Microsoft Excel | هر دو | بی نهایت | |
| Text file | هر دو | بی نهایت | |
| Salesforce | هر دو | بی نهایت | |
| OData | هر دو | بی نهایت | |
| Google Analytics | هر دو | بی نهایت | |
| Tableau Data Server | هر دو | بی نهایت | در نسخه 9.0 پشتیبانی می شود. |
| Vertica | فقط Left | 10 | |
| Oracle | فقط Left | 10 | |
| MySQL | هردو | 10 | |
| PostgreSQL | فقط Left از نسخه 9.0 باقی مانده است. هر دو (Left/Right) نسخه 9.0 و بالاتر | 10 | |
| Teradata | فقط Left | 10 | نسخه 14 به بعد |
| Amazon Redshift | فقط Left | 10 | |
| Aster Database | فقط Left | 10 | |
| Google BigQuery | فقط Left | 10 | |
| Hortonworks Hadoop Hive | فقط Left | 10 | |
| Cloudera Hadoop | فقط Left | 10 | Impala از نسخه 2.3.0 پشتیبانی می کند. |
| Microsoft SQL Server | هر دو | 10 | 2008 به بعد |
توابع رشته string functions در تبلو
برای خرید لایسنس نرم افزار Tableau ، میتوانید از خدمات ما استفاده نموده و درخواست خود را از طریق فرم زیر ثبت نمایید.



{kind=link}
بدون دیدگاه