استخراج داده ها (Extract Data)
یک اکسترکت یا استخراج داده (data extract) زیرمجموعهای از اطلاعات است که به طور جداگانه از مجموعه داده اصلی ذخیره میشود. این کار دو هدف را دنبال میکند: بهبود عملکرد و استفاده از قابلیتهای Tableau که ممکن است در دادههای اصلی در دسترس یا پشتیبانی نشوند. با ایجاد یک اکسترکت داده، میتوانید با اعمال فیلترها و تنظیم محدودیتهای دیگر، به طور موثری حجم کلی دادهها را کاهش دهید.
پس از ایجاد یک استخراج داده، میتوان آن را با آخرین دادهها از منبع اصلی تازهسازی کرد. در طول فرآیند تازهسازی، شما انعطافپذیری دارید که بین یک تازهسازی کامل (full refresh)، که تمام محتوای موجود در اکسترکت را جایگزین میکند، یا یک تازهسازی افزایشی (incremental refresh)، که فقط ردیفهای جدید را از آخرین تازهسازی شامل میشود، یکی را انتخاب کنید.
مزایای Extract ها
- مدیریت مجموعه دادههای بزرگ: Extract ها میتوانند حجم عظیمی از دادهها را، حتی تا میلیاردها ردیف، مدیریت کنند. این به کاربران امکان میدهد تا با مجموعههای داده گسترده به طور کارآمد کار کنند.
- عملکرد بهبود یافته: تعامل با نماهایی که از منابع داده Extract استفاده میکنند، در مقایسه با نماهایی که مستقیماً به دادههای اصلی متصل هستند، عملکرد بهتری دارد. Extract ها عملکرد پرسوجو را بهینه میکنند و در نتیجه تحلیل و بصریسازی سریعتر دادهها را به همراه دارند.
- قابلیتهای پیشرفته: Extract ها دسترسی به قابلیتهای اضافی Tableau را فراهم میکنند که ممکن است توسط منبع داده اصلی در دسترس یا پشتیبانی نشوند، مانند توابع خاص.
- دسترسی آفلاین به دادهها (Tableau Desktop): Extract ها امکان دسترسی آفلاین به دادهها را فراهم میکنند. این بدان معناست که حتی زمانی که منبع داده اصلی در دسترس نیست، کاربران همچنان میتوانند دادهها را به صورت محلی ذخیره، دستکاری و با آنها کار کنند.
ایجاد یک Extract
روشهای متعددی برای ایجاد یک Extract وجود دارد، اما رویکرد اصلی در ادامه توضیح داده شده است.
- پس از اتصال به دادههای خود و راهاندازی منبع داده در صفحه Data Source، در گوشه بالا سمت راست، Extract را انتخاب کرده، و سپس روی لینک Edit کلیک کنید تا کادر محاورهای Extract Data باز شود.

- هر بخش را باز کنید تا گزینههای آن را ببینید، یا Expand All را انتخاب کنید. اطلاعات بیشتر در مورد هر بخش در ادامه این موضوع ارائه شده است.
- Data Storage (ذخیرهسازی داده): بین Logical Tables (جداول منطقی) یا Physical Tables (جداول فیزیکی) تغییر دهید.
- Filters (فیلترها): فیلترها را برای محدود کردن میزان دادههای استخراج شده بر اساس فیلدها و مقادیر آنها تنظیم کنید.
- Aggregation (تجمیع): Aggregate data for visible dimensions (تجمیع دادهها برای ابعاد قابل مشاهده) را انتخاب کنید تا معیارهای (measures) را با استفاده از تجمیع پیشفرض خود تجمیع کنید. همچنین میتوانید Roll up dates (تاریخها را جمع کنید) را به یک سطح تاریخ مشخص مانند سال، ماه و غیره انتخاب کنید.
- Number of Rows (تعداد ردیفها): تعداد ردیفهایی که میخواهید استخراج کنید را تنظیم کنید. میتوانید All rows (همه ردیفها)، Sample (نمونه) یا Top N rows (بالاترین N ردیف) را استخراج کنید.
- Incremental refresh (تازهسازی افزایشی): یک تازهسازی افزایشی را بر اساس یک ستون خاص و محدوده تاریخ تنظیم کنید. همچنین میتوانید انتخاب کنید که آیا ردیفهای آخر جایگزین شوند یا اضافه شوند.
- پس از اتمام، Save Settings (ذخیره تنظیمات) را انتخاب کنید.
- تب Sheet را انتخاب کنید. این کار شروع به ایجاد Extract میکند.
- سپس، مکانی را برای ذخیره Extract انتخاب کنید.
- یک نام فایل برای Extract وارد کنید. Save (ذخیره) را انتخاب کنید. اگر کادر محاورهای Save نمایش داده نمیشود.
توضیحات تنظیمات Extract
میتوانید تنظیمات متعددی را هنگام ایجاد یک Extract پیکربندی کنید.
ذخیرهسازی داده (Data Storage)
در قسمت Data Storage میتوانید جداول منطقی یا فیزیکی را انتخاب کنید. جداول منطقی دادهها را در یک جدول Extract برای هر جدول منطقی در منبع داده ذخیره میکنند. از سوی دیگر، جداول فیزیکی دادهها را در یک جدول Extract برای هر جدول فیزیکی در منبع داده ذخیره میکنند.
هر دو گزینه جداول منطقی و جداول فیزیکی تنها بر نحوه ذخیرهسازی دادهها در Extract شما تأثیر میگذارند. این گزینهها بر نحوه نمایش جداول در Extract شما در صفحه Data Source تأثیری ندارند.
به عنوان مثال، فرض کنید Extract شما از یک جدول منطقی تشکیل شده است که شامل سه جدول فیزیکی است. اگر فایل استخراج (.hyper) را که برای استفاده از گزینه پیشفرض، جداول منطقی، پیکربندی شده است، مستقیماً باز کنید، یک جدول در صفحه Data Source مشاهده میکنید. با این حال، اگر Extract را با استفاده از فایل منبع داده بستهبندی شده (.tdsx) یا فایل منبع داده (.tdsx) با فایل استخراج (.hyper) مربوطه آن باز کنید، هر سه جدول را در صفحه Data Source مشاهده میکنید.
جداول منطقی (Logical Tables)
Tableau از جداول منطقی به عنوان ساختار پیشفرض برای ذخیرهسازی دادههای Extract استفاده میکند. Tableau عموماً توصیه میکند که هنگام راهاندازی و کار با Extracts، از گزینه پیشفرض ذخیرهسازی داده، جداول منطقی، استفاده کنید.
بسیاری از قابلیتهایی که ممکن است بخواهید، مانند فیلترهای Extract، تجمیع، Top N، یا توابع pass-through (RAWSQL)، فقط در صورتی در دسترس شما هستند که از گزینه جداول منطقی استفاده کنید. با این حال، نمیتوانید دادهها را به Extract هایی که بیش از یک جدول منطقی دارند، اضافه کنید.
اگر گزینه جدول منطقی را انتخاب کنید و Extract شما شامل جوینها باشد، جوینها هنگام ایجاد Extract اعمال میشوند.
جداول فیزیکی (Physical Tables)
این گزینه جوینها را در زمان پرسوجو انجام میدهد و در صورت برآورده شدن تمام شرایط زیر توسط دادههای شما، میتواند به طور بالقوه عملکرد را بهبود بخشد و اندازه فایل Extract را کاهش دهد:
- همه جوینها بین جداول فیزیکی از نوع جوین برابری (=) باشند.
- انواع داده ستونهای استفاده شده برای روابط یا جوینها یکسان باشند.
- هیچ تابع pass-through (RAWSQL) استفاده نشده باشد.
- هیچ تازهسازی افزایشی پیکربندی نشده باشد.
- هیچ فیلتر Extract پیکربندی نشده باشد.
- هیچ Top N یا نمونهگیری پیکربندی نشده باشد.
- نیازی به افزودن داده به Extract نباشد.
نکاتی برای کار با جداول فیزیکی
- Extract هایی که بزرگتر از حد انتظار هستند: برای تعیین اینکه آیا Extract بزرگتر از حد خود است، مجموع ردیفها در استخراج با استفاده از گزینه Logical Tables باید بیشتر از مجموع ردیفهای تمام جداول ترکیبی قبل از ایجاد استخراج باشد. اگر با این سناریو مواجه شدید، سعی کنید از گزینه Physical Tables استفاده کنید.
- گزینههای فیلتر کردن: هنگام استفاده از گزینه Physical Tables، سایر گزینهها برای کمک به کاهش دادهها در استخراج شما، مانند فیلترهای Extract، تجمیع، Top N و Sampling غیرفعال میشوند. اگر نیاز به کاهش دادهها در یک Extract دارید که از گزینه Physical Tables استفاده میکند، قبل از وارد کردن دادهها به Tableau Desktop با استفاده از یکی از پیشنهادات زیر، دادهها را فیلتر کنید:
- تمام جوینها بین جداول فیزیکی از نوع جوین برابری (=) باشند.
- به دادههای خود متصل شوید و فیلترها را با استفاده از SQL سفارشی تعریف کنید. به جای اتصال به یک جدول پایگاه داده، با استفاده از SQL سفارشی به دادههای خود متصل شوید. هنگام ایجاد پرسوجوی SQL سفارشی خود، مطمئن شوید که شامل سطح مناسبی از فیلترینگ است که برای کاهش دادهها در Extract خود به آن نیاز دارید.
- یک نما در پایگاه داده تعریف کنید. اگر دسترسی نوشتن به پایگاه داده خود را دارید، تعریف یک نمای پایگاه داده را در نظر بگیرید که فقط دادههایی را که برای Extract خود نیاز دارید، شامل شود و سپس از Tableau Desktop به نمای پایگاه داده متصل شوید.
- امنیت در سطح ردیف با Extracts: اگر میخواهید دادههای Extract را در سطح ردیف امن کنید، استفاده از گزینه Physical Tables روش توصیه شده برای دستیابی به این سناریو است.
فیلترها (Filters)
از فیلترها برای محدود کردن میزان دادههای استخراج شده بر اساس فیلدها و مقادیر آنها استفاده کنید.
نکته: فیلترهای Extract بر روی جداول منطقی برای منابع داده با یک جدول پایه واحد فراگیر (pervasive) هستند (یعنی به کل منبع داده اعمال میشوند). برای منابع داده با چندین جدول پایه با استفاده از روابط چندفاکتور (multi-fact relationships)، فیلترهای Extract به ازای هر جدول (per-table) هستند و فقط به خود جدول منطقی اعمال میشوند.
تجمیع (Aggregation)
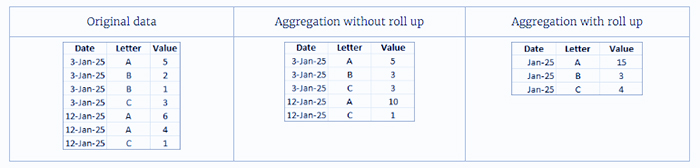
تجمیع به شما امکان میدهد تا معیارها را تجمیع کنید. همچنین میتوانید Roll up dates (تاریخها را جمع کنید) را به یک سطح تاریخ مشخص مانند سال، ماه و غیره انتخاب کنید. مثالها نحوه استخراج دادهها را برای هر گزینه تجمیعی که میتوانید انتخاب کنید، نشان میدهند:
- دادههای اصلی (Original data): هر رکورد به عنوان یک ردیف جداگانه نشان داده میشود. هفت ردیف در دادههای اصلی وجود دارد.
- تجمیع دادهها برای ابعاد قابل مشاهده (بدون جمع کردن) (Aggregate data for visible dimensions (no roll up)): رکوردهای با تاریخ و حرف یکسان در یک ردیف واحد تجمیع شدهاند. پنج ردیف در Extract وجود دارد.
- تجمیع دادهها برای ابعاد قابل مشاهده (تاریخها را به ماه جمع کنید) (Aggregate data for visible dimensions (roll up dates to Month)): تاریخها به سطح ماه جمع شدهاند و رکوردهای با منطقه یکسان در یک ردیف واحد تجمیع شدهاند. سه ردیف در Extract وجود دارد.
تعداد ردیفها (Number of rows)
میتوانید همه ردیفها یا بالاترین N ردیف را استخراج کنید. Tableau ابتدا هر فیلتر و تجمیع را اعمال میکند و سپس تعداد ردیفها را از نتایج فیلتر شده و تجمیع شده استخراج میکند. گزینههای تعداد ردیفها به نوع منبع دادهای که از آن استخراج میکنید بستگی دارد. ممکن است گزینه نمونهگیری (sampling) را در کادر محاورهای Extract Data نبینید زیرا برخی از منابع داده از نمونهگیری پشتیبانی نمیکنند.
نکته(ها): هر فیلدی که ابتدا در صفحه Data Source یا در تب sheet پنهان میکنید، از Extract حذف خواهد شد. برای حذف فیلدهای پنهان شده از Extract، روی دکمه Hide All Unused Fields (پنهان کردن تمام فیلدهای استفاده نشده) کلیک کنید.
تازهسازی افزایشی (Incremental Refresh)
بیشتر منابع داده از تازهسازی افزایشی پشتیبانی میکنند. به جای تازهسازی کل Extract، میتوانید یک تازهسازی را پیکربندی کنید تا فقط ردیفهایی که از آخرین باری که دادهها را استخراج کردهاید، جدید هستند، اضافه شوند.
بعنوان مثال، ممکن است یک منبع داده داشته باشید که روزانه با تراکنشهای فروش جدید بهروز میشود. به جای بازسازی کل Extract هر روز، میتوانید تراکنشهای جدیدی که در آن روز رخ دادهاند را اضافه کنید.
نکاتی برای تازهسازی افزایشی
تازهسازی افزایشی:
- در قسمت Number of Rows (تعداد ردیفها)، باید All Rows (همه ردیفها) را انتخاب کنید.
- تازهسازی افزایشی در صورت فعال کردن Aggregation (تجمیع) در دسترس نیست.
تنظیمات پیشرفته (Advanced Settings):
- تنظیمات پیشرفته با فیلترها سازگار نیستند.
نکات مربوط به Extract
ورکبوک خود را برای حفظ اتصال به Extract ذخیره کنید
پس از ایجاد یک Extract، ورکبوک شروع به استفاده از نسخه Extract شده دادههای شما میکند. با این حال، اتصال به نسخه Extract شده دادههای شما تا زمانی که ورکبوک را ذخیره نکنید، ذخیره نمیشود. این بدان معناست که اگر ورکبوک را بدون ذخیره کردن آن ببندید، در دفعه بعد که آن را باز میکنید، ورکبوک به منبع داده اصلی متصل خواهد شد.
جابهجایی بین دادههای نمونهبرداری شده و Extract کامل
هنگام کار با یک Extract بزرگ، ایجاد یک نمونه کوچکتر از دادهها میتواند مفید باشد. این به شما امکان میدهد نمای خود را بدون نیاز به اجرای پرسوجوهای طولانی هر بار که یک فیلد را به تحلیل خود اضافه میکنید، تنظیم کنید. میتوانید به راحتی بین استفاده از دادههای نمونه و منبع داده کامل با انتخاب گزینه مناسب در منوی Data جابهجا شوید.
مستقیماً به Extract متصل نشوید
هنگامی که Extracts را در رایانه خود ذخیره میکنید، میتوانید مستقیماً با استفاده از یک Tableau Desktop جدید به آنها متصل شوید. با این حال، به دلایل زیر توصیه نمیشود:
- نام جداول ممکن است متفاوت باشد: Extract ها از نامگذاری خاصی استفاده میکنند تا اطمینان حاصل شود که هر جدول دارای یک نام منحصر به فرد است که ممکن است درک آن دشوار باشد.
- نمیتوانید Extract را بهروزرسانی یا تازهسازی کنید: وقتی مستقیماً به یک Extract متصل میشوید، Tableau آن را به عنوان منبع اصلی داده در نظر میگیرد، نه یک کپی. این بدان معناست که نمیتوانید آن را به منبع داده اصلی خود پیوند دهید.
- ساختار و روابط بین جداول از بین خواهد رفت: ترتیب و اتصالات بین جداول در فایل .tds ذخیره میشوند، نه در فایل .hyper. بنابراین، وقتی مستقیماً به فایل .hyper متصل میشوید، این اطلاعات را از دست میدهید. اگر از ذخیرهسازی جداول منطقی برای Extract استفاده میکنید، هیچ ارجاعی به جداول فیزیکی اصلی نخواهید دید.
اگر به یک اتصال مجازی با توابع کاربری در سیاست داده متصل هستید، از Extract استفاده نکنید
اگر یک اتصال مجازی دارای یک سیاست داده باشد که شامل توابع کاربری (برای مثال، USERNAME()) است و شما از یک ورکبوک یا منبع داده به آن متصل شده و در آنجا یک Extract ایجاد میکنید، Extract فقط شامل ردیفهایی خواهد بود که با سیاست داده اتصال مجازی در زمان ایجاد Extract مطابقت دارند. برای استفاده از یک اتصال مجازی با توابع کاربری در سیاست داده، به جای Extract، از یک اتصال زنده (live connection) از ورکبوک یا منبع داده به اتصال مجازی استفاده کنید.
حذف Extract از ورکبوک
میتوانید در هر زمان یک Extract را از منوی Data با انتخاب منبع داده استخراج شده > Extract > Remove حذف کنید.
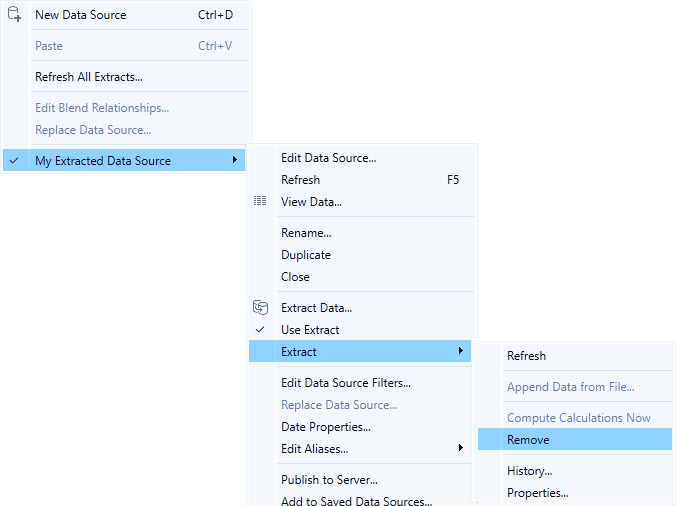
هنگام حذف یک Extract، میتوانید انتخاب کنید که Remove the extract from the workbook only (فقط Extract را از ورکبوک حذف کن) یا Remove and delete the extract file (Extract را حذف و فایل آن را پاک کن). گزینه دوم Extract را از هارد دیسک شما حذف میکند.
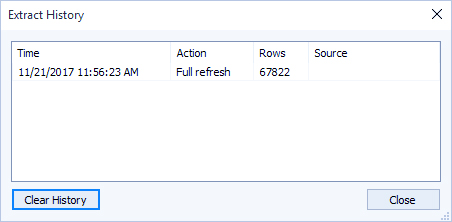
مشاهده تاریخچه Extract (Tableau Desktop)
میتوانید با انتخاب یک منبع داده در منوی Data و سپس انتخاب Extract > History، زمان آخرین بهروزرسانی Extract و سایر جزئیات را مشاهده کنید.
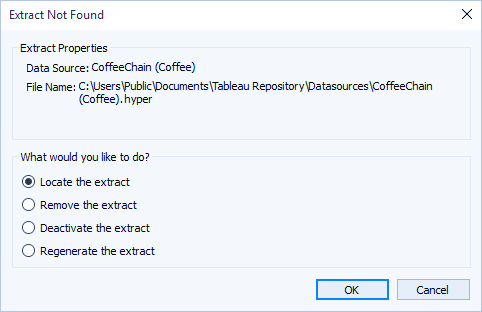
اگر ورکبوکی را باز کنید که با یک Extract ذخیره شده است و Tableau نتواند Extract را پیدا کند، در کادر محاورهای Extract Not Found (Extract پیدا نشد) هنگام درخواست، یکی از گزینههای زیر را انتخاب کنید:
- Locate the extract (Extract را پیدا کن): این گزینه را انتخاب کنید اگر Extract وجود دارد اما در مکانی نیست که Tableau در ابتدا آن را ذخیره کرده است. روی OK کلیک کنید تا کادر محاورهای Open File باز شود که در آن میتوانید مکان جدید فایل Extract را مشخص کنید.
- Remove the extract (Extract را حذف کن): اگر دیگر نیازی به Extract ندارید، این گزینه را انتخاب کنید. این معادل بستن منبع داده است. تمام ورکشیتهای باز که به منبع داده اشاره میکنند، حذف میشوند.
- Deactivate the extract (Extract را غیرفعال کن): از منبع داده اصلی که Extract از آن ایجاد شده است، به جای Extract استفاده کنید.
- Regenerate the extract (Extract را بازسازی کن): Extract را دوباره ایجاد میکند. تمام فیلترها و سایر سفارشیسازیهایی که در ابتدا هنگام ایجاد Extract مشخص کردهاید، به طور خودکار اعمال میشوند.
عیبیابی Extracts
- ایجاد Extract زمان زیادی میبرد: بسته به اندازه مجموعه داده شما، ایجاد یک Extract ممکن است زمان زیادی طول بکشد. با این حال، پس از اینکه دادهها را استخراج کرده و در رایانه خود ذخیره کردید، عملکرد میتواند بهبود یابد.
- Extract ایجاد نمیشود: اگر مجموعه داده شما شامل تعداد زیادی ستون (مثلاً در هزاران) باشد، در برخی موارد Tableau ممکن است نتواند Extract را ایجاد کند. اگر با مشکل مواجه شدید، استخراج ستونهای کمتر یا تغییر ساختار دادههای زیرین را در نظر بگیرید.
- کادر محاورهای Save نمایش داده نمیشود یا Extract از یک .twbx ایجاد نمیشود: اگر روش قبل از این را برای استخراج دادهها از یک ورکبوک بستهبندی شده دنبال کنید، کادر محاورهای Save نمایش داده نمیشود. هنگامی که یک Extract از یک ورکبوک بستهبندی شده (.twbx) ایجاد میشود، فایل Extract به طور خودکار در بسته فایلهای مرتبط با ورکبوک بستهبندی شده ذخیره میشود. برای دسترسی به فایل Extract که از ورکبوک بستهبندی شده ایجاد کردهاید، باید ورکبوک را از حالت بستهبندی خارج کنید.
بهروزرسانی قابلیتهای Extract
تازهسازی زیرمجموعه برای Extracts افزایشی
در نسخههای 2024.2 و جدیدتر Tableau، میتوانید یک دوره زمانی اضافی را برای استخراج مجدد دادههای قبلاً استخراج شده و ثبت هرگونه تغییری که ممکن است رخ داده باشد، مشخص کنید.
تازهسازی افزایشی
از نسخه 2024.1 به بعد، Tableau قابلیتی را معرفی میکند که به کاربران امکان میدهد تازهسازیهای افزایشی را بر روی Extracts با استفاده از یک ستون کلید غیر منحصربهفرد انجام دهند. یک رابط کاربری جدید وجود دارد که از این تنظیمات پیشرفته پشتیبانی میکند.
این بهروزرسانی همچنین یک گام اضافی را در فرآیند استخراج معرفی میکند. در طول یک تازهسازی افزایشی، Tableau ابتدا ردیفهای Extract را که با بالاترین مقدار قبلاً ثبت شده مطابقت دارند، حذف میکند. متعاقباً، Tableau تمام ردیفهایی را که دارای مقداری بالاتر یا مساوی با بالاترین مقدار قبلی هستند، پرسوجو میکند. این رویکرد تضمین میکند که ردیفهای حذف شده، همراه با ردیفهای تازه اضافه شده، در نظر گرفته میشوند.
Extracts در وب
از نسخه 2020.4 به بعد، Extracts در وبنویسی (web authoring) و سرور محتوا (content server) در دسترس هستند. اکنون، دیگر نیازی به استفاده از Tableau Desktop برای استخراج منابع داده خود ندارید.
Extracts جدول منطقی و فیزیکی
با معرفی جداول منطقی و فیزیکی در مدل داده Tableau در نسخه 2020.2، گزینههای ذخیرهسازی Extract از Single Table و Multiple Tables به Logical Tables و Physical Tables تغییر کردهاند. این گزینهها بهتر نحوه ذخیرهسازی Extracts را توضیح میدهند.
منسوخ شدن فرمت .tde
هنگامی که یک Extract ایجاد میکنید، از فرمت .hyper استفاده میکند. Extracts با فرمت .hyper از موتور داده بهبود یافته بهره میبرند که از عملکرد تحلیلی و پرسوجویی سریعتر برای مجموعههای داده بزرگتر پشتیبانی میکند. از مارس 2023، Extracts با فرمت .tde در Tableau Cloud، Tableau Public و Tableau Server (نسخه 2023.1.0) منسوخ شدهاند. نسخه 2024.2 آخرین نسخهای است که میتواند فایلهای با فرمت .tde را باز کند.
تغییرات در مقادیر و نشانهها در نما
برای بهبود کارایی و مقیاسپذیری Extract، مقادیر در Extracts میتوانند به صورت متفاوتی از برخی منابع داده محاسبه شوند. تغییرات در نحوه محاسبه مقادیر میتواند بر نحوه پر شدن نشانهها در نمای شما تأثیر بگذارد. در برخی موارد نادر، این تغییرات میتوانند باعث تغییر شکل یا خالی شدن نمای شما شوند. این تغییرات همچنین میتوانند برای منابع داده چند اتصالی، منابع دادهای که از اتصالات زنده به دادههای مبتنی بر فایل استفاده میکنند، منابع دادهای که به دادههای Google Sheets متصل میشوند، منابع داده مبتنی بر ابر، منابع داده فقط Extract و منابع داده WDC اعمال شوند.
فرمت مقادیر تاریخ و زمان
Extract ها تابع قوانین ثابت و سختگیرانهای هستند که نحوه تفسیر رشتههای تاریخ از طریق توابع DATE، DATETIME و DATEPARSE را تعیین میکنند. این بر نحوه تجزیه (parsing) تاریخها، یا فرمتها و الگوهای تاریخ مجاز برای این توابع تأثیر میگذارد. به طور خاص، قوانین را میتوان به شرح زیر تعمیم داد:
- تاریخها بر اساس ستون ارزیابی و سپس تجزیه میشوند، نه بر اساس ردیف.
- تاریخها بر اساس لوکال (locale) محل ایجاد ورکبوک ارزیابی و سپس تجزیه میشوند، نه بر اساس لوکال رایانهای که ورکبوک در آن باز میشود.
این قوانین به Extract ها امکان میدهد کارآمدتر باشند و نتایجی تولید کنند که با پایگاه دادههای تجاری سازگار است.
علل رایج تغییرات در مقادیر تاریخ/زمان
- در جایی که تاریخ مبهم است و میتواند به روشهای مختلفی تفسیر شود، تاریخ بر اساس فرمتی که Tableau برای آن ستون تعیین کرده است، تفسیر خواهد شد. برای برخی مثالها، به سناریو 1 در ادامه مراجعه کنید.
- هنگامی که یک تابع باید یک رشته تاریخ با فرمت YYYY-MM-DD (ISO) را تجزیه کند. برای مثالی، به سناریو 2 مراجعه کنید.
- هنگامی که یک تابع سالها را تجزیه میکند، به صورت زیر تفسیر میشود:
- سال “07” به عنوان “2007” تفسیر میشود.
- سال “17” به عنوان “2017” تفسیر میشود.
- سال “30” به عنوان “2030” تفسیر میشود.
- سال “69” به عنوان “2069” تفسیر میشود.
- سال “70” به عنوان “1970” تفسیر میشود.
علل رایج مقادیر Null
- هنگامی که یک تابع باید چندین فرمت تاریخ را در یک ستون واحد تجزیه کند. پس از اینکه Tableau فرمت تاریخ را تعیین کرد، تمام تاریخهای دیگر در ستون که از آن فرمت منحرف میشوند، مقادیر Null میشوند. برای برخی مثالها، به سناریو 1 در ادامه مراجعه کنید.
- هنگامی که یک تابع باید یک رشته تاریخ با فرمت YYYY-MM-DD (ISO) را تجزیه کند. مقادیری که از آنچه برای “YYYY”، یا “MM”، یا “DD” مجاز است فراتر میروند، باعث مقادیر Null میشوند. برای مثالی، به سناریو 2 مراجعه کنید.
- هنگامی که یک تابع باید مقادیر تاریخ را که حاوی کاراکترهای دنبالهدار هستند، تجزیه کند. به عنوان مثال، پسوندهای منطقه زمانی و صرفهجویی در روشنایی روز و کلمات کلیدی، مانند “midnight” باعث مقادیر Null میشوند.
- هنگامی که یک تابع باید یک تاریخ یا زمان نامعتبر را تجزیه کند. به عنوان مثال، 32/3/2024 باعث یک مقدار Null میشود. در مثال دیگر، 25:01:61 باعث یک مقدار Null میشود.
- هنگامی که یک تابع باید ورودیهای متناقض را تجزیه کند. به عنوان مثال، فرض کنید الگو ‘dd.MM (MMMM) y’ باشد و رشته ورودی ‘1.09 (August) 2024’ باشد، که در آن هم “9” و هم “August” ماهها هستند. نتیجه یک مقدار Null است زیرا مقادیر ماه یکسان نیستند.
- هنگامی که یک تابع باید الگوهای متناقض را تجزیه کند. به عنوان مثال، الگویی که ترکیبی از سال میلادی (y) و هفته ISO (ww) را مشخص میکند، باعث مقادیر Null میشود.
سناریو 1
فرض کنید یک ورکبوک دارید که در یک لوکال انگلیسی ایجاد شده و از منبع داده Extract با فرمت .tde استفاده میکند. جدول پس از این، یک ستون از دادههای رشتهای موجود در منبع داده Extract را نشان میدهد.

بر اساس لوکال انگلیسی خاص، فرمت ستون تاریخ برای پیروی از فرمت MDY (ماه، روز و سال) تعیین شد. جداول زیر نشان میدهند که Tableau بر اساس این لوکال چه چیزی را هنگام استفاده از تابع DATE برای تبدیل مقادیر رشتهای به مقادیر تاریخ نمایش میدهد.
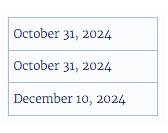
اگر Extract در یک لوکال آلمانی باز شود، موارد زیر را مشاهده میکنید:

با این حال، پس از باز شدن Extract در یک لوکال آلمانی با استفاده از نسخه 10.5 و بالاتر، فرمت DMY (روز، ماه و سال) لوکال آلمانی به شدت اعمال میشود و باعث یک مقدار Null میشود زیرا یکی از مقادیر از فرمت DMY پیروی نمیکند.
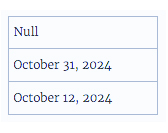
سناریو 2
فرض کنید یک ستون از دادههای رشتهای در منبع داده دارید.

از آنجا که تاریخ از فرمت ISO استفاده میکند، ستون تاریخ همیشه از فرمت YYYY-MM-DD پیروی میکند. جداول زیر نشان میدهند که Tableau چه چیزی را هنگام استفاده از تابع DATE برای تبدیل مقادیر رشتهای به مقادیر تاریخ نمایش میدهد.
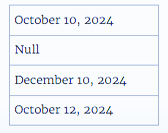
ترتیب مرتبسازی و حساسیت به حروف (Sort order and case sensitivity)
Extract ها از پشتیبانی collation برخوردارند و بنابراین میتوانند مقادیر رشتهای را که دارای اکسان (accents) هستند یا به صورتهای مختلف حروفچینی شدهاند (case-differently)، به طور مناسبتری مرتب کنند.
به عنوان مثال، فرض کنید یک جدول از مقادیر رشتهای دارید. از نظر ترتیب مرتبسازی، این بدان معناست که یک مقدار رشتهای مانند Égypte اکنون به طور مناسب پس از Estonie و قبل از Fidji لیست میشود.
در مورد حروفچینی (casing)، همان مقادیر رشتهای منحصر به فرد در نظر گرفته میشوند و بنابراین به عنوان مقادیر فردی ذخیره میشوند.
شکستن گرهها در پرسوجوهای Top N (Breaking ties in Top N queries)
یک پرسوجوی Top N در Extract شما میتواند مقادیر تکراری را برای یک موقعیت خاص در یک رتبه تولید کند. به عنوان مثال، فرض کنید یک فیلتر Top 3 ایجاد کردهاید. موقعیتهای 3، 4 و 5 مقادیر یکسانی دارند. فیلتر Top 1، 2 و 5 موقعیت را برمیگرداند.
دقت مقادیر ممیز شناور (Precision of floating-point values)
Extract ها در بهرهگیری از منابع سختافزاری موجود در یک رایانه بهتر عمل میکنند و بنابراین قادر به انجام عملیات ریاضی به روشی بسیار موازی هستند. به همین دلیل، اعداد حقیقی میتوانند توسط Extracts با فرمت .hyper به ترتیبهای مختلفی تجمیع شوند. هنگامی که اعداد به ترتیبهای مختلفی تجمیع میشوند، ممکن است هر بار که تجمیع محاسبه میشود، مقادیر متفاوتی را در نمای خود پس از نقطه اعشار مشاهده کنید. این به این دلیل است که جمع و ضرب ممیز شناور لزوماً انجمنی نیستند.
یعنی (a + b) + c لزوماً با a + (b + c) یکسان نیست. همچنین، اعداد حقیقی میتوانند به ترتیبهای مختلفی تجمیع شوند زیرا ضرب ممیز شناور لزوماً توزیعپذیر نیست. یعنی (a x b) x c لزوماً با a x b x c یکسان نیست. این نوع رفتار گرد کردن ممیز شناور در استخراج ها با فرمت .hyper شبیه رفتار گرد کردن ممیز شناور در پایگاه دادههای تجاری است.
به عنوان مثال، فرض کنید ورکبوک شما شامل یک فیلتر اسلایدر (slider filter) روی یک فیلد تجمیع شده شامل مقادیر ممیز شناور است. از آنجا که دقت مقادیر ممیز شناور تغییر کرده است، ممکن است فیلتر اکنون یک علامت (mark) را که مرز بالا یا پایین محدوده فیلتر را تعریف میکند، حذف کند. عدم وجود این اعداد میتواند باعث یک نمای خالی شود. برای حل این مشکل، اسلایدر را روی فیلتر حرکت دهید یا فیلتر را حذف کرده و دوباره اضافه کنید.
دقت تجمیعها (Accuracy of aggregations)
استخراج ها با بهرهگیری بهتر از منابع سختافزاری موجود در یک رایانه برای مجموعههای داده بزرگ بهینهسازی شدهاند و بنابراین قادر به محاسبه تجمیعها به روشی بسیار موازی هستند. به همین دلیل، تجمیعهای انجام شده توسط Extracts با فرمت .hyper میتوانند نتایجی شبیه به پایگاه دادههای تجاری داشته باشند تا نتایج نرمافزارهایی که در محاسبات آماری تخصص دارند.
اگر با یک مجموعه داده کوچک کار میکنید یا به سطح بالاتری از دقت نیاز دارید، انجام تجمیعها را از طریق خطوط مرجع (reference lines)، آمار کارت خلاصه (summary card statistics) یا توابع محاسبات جدول (table calculation functions) مانند واریانس، انحراف معیار، همبستگی یا کوواریانس در نظر بگیرید.
API ها
میتوانید از Extract API برای ایجاد Extracts با فرمت .hyper استفاده کنید. برای وظایفی مانند انتشار Extracts، میتوانید از Tableau Server REST API یا کتابخانه Tableau Server Client (Python) استفاده کنید. برای وظایف تازهسازی، میتوانید از Tableau Server REST API نیز استفاده کنید.
برای خرید لایسنس نرم افزار Tableau ، میتوانید از خدمات ما استفاده نموده و درخواست خود را از طریق فرم زیر ثبت نمایید.



 در Tableau Desktop){kind=link}
بدون دیدگاه