
استفاده از روابط برای تحلیل دادههای چندجدولی Multi-table
جدولهایی که به بوم (Canvas) میکشید، با استفاده از روابط (Relationships) ترکیب میشوند. روابط روشی منعطف برای ترکیب دادهها در تحلیلهای چندجدولی Multi-table در Tableau هستند.
رابطه را مانند یک قرارداد بین دو جدول در نظر بگیرید. زمانی که در حال ساخت تصویرسازی (Viz) با فیلدهایی از این جدولها هستید، Tableau دادهها را بر اساس آن قرارداد فراخوانی میکند و پرسوجویی با اتصالهای مناسب ایجاد مینماید.
توصیه میکنیم برای ترکیب دادهها، ابتدا از روابط استفاده کنید؛ زیرا این روش باعث میشود آمادهسازی دادهها و تحلیل آنها سادهتر و شهودیتر باشد.
آیا در حال ساخت یک منبع داده و ورکبوک جدید هستید؟
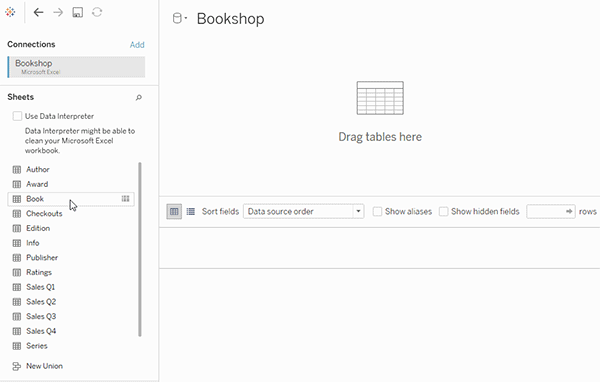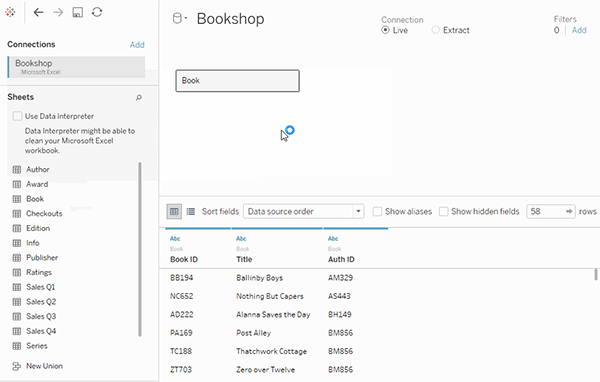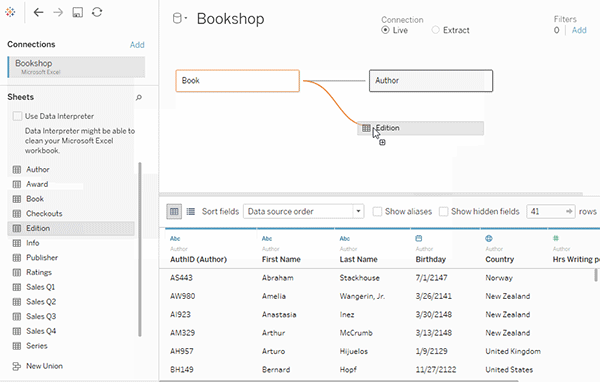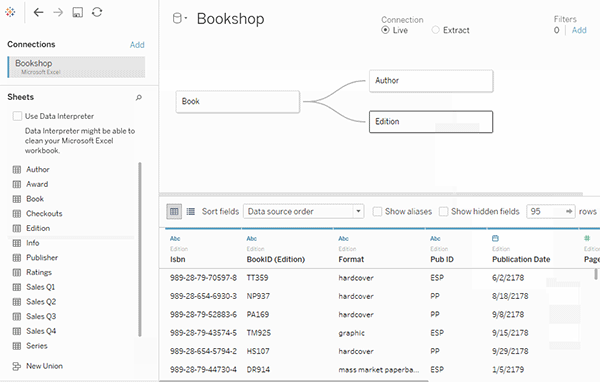
برای شروع ساخت منبع داده خود، یک جدول را به بوم صفحه Data Source بکشید.
منبع داده میتواند شامل یک جدول واحد باشد که تمام فیلدهای ابعاد (Dimensions) و اندازهگیری (Measures) مورد نیاز برای تحلیل را در خود دارد.
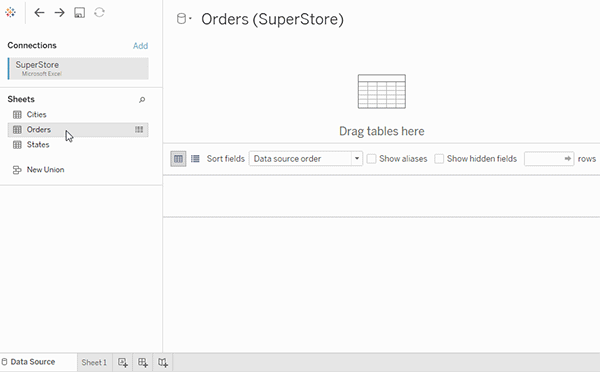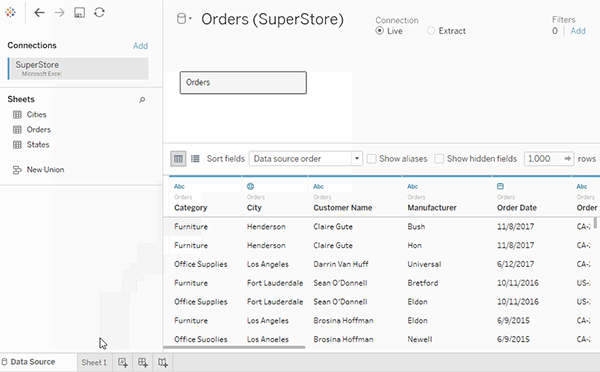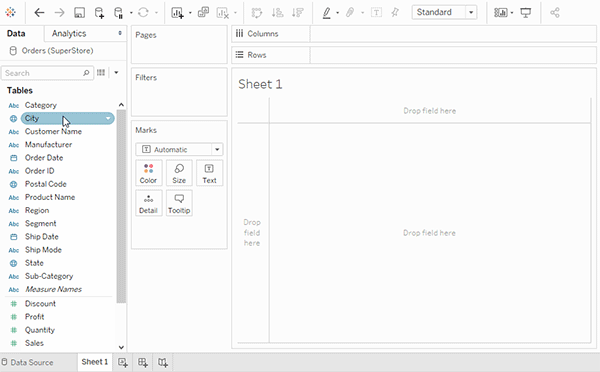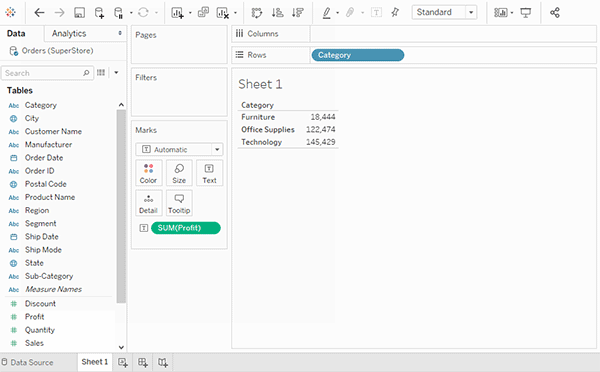
یا میتوانید با کشیدن جداول بیشتر و تعریف روابط آنها، یک منبع داده Multi-table ایجاد کنید.
آیا در حال باز کردن یک ورکبوک یا منبع داده قدیمی هستید؟
هنگامی که یک ورکبوک یا منبع داده مربوط به نسخههای قبل از 2020.2 را در نسخه 2020.2 باز میکنید، منبع داده شما بهصورت یک جدول منطقی واحد در بوم ظاهر میشود که نام آن ممکن است “Migrated Data” یا همان نام اصلی جدول باشد.
دادههای شما حفظ میشوند و میتوانید مانند گذشته به استفاده از ورکبوک ادامه دهید.
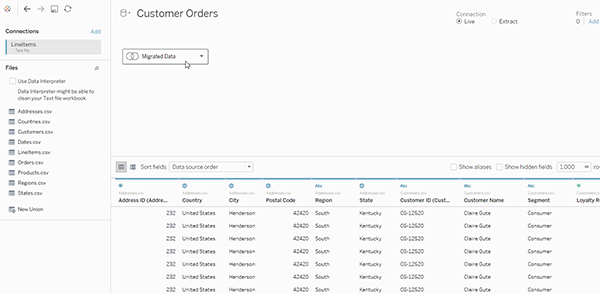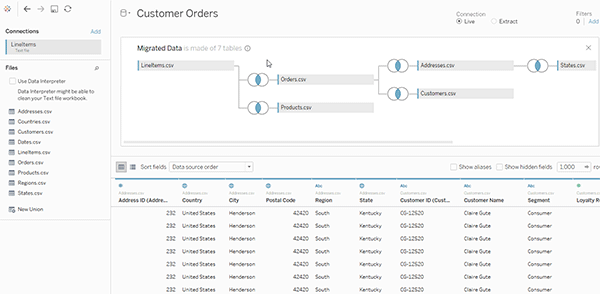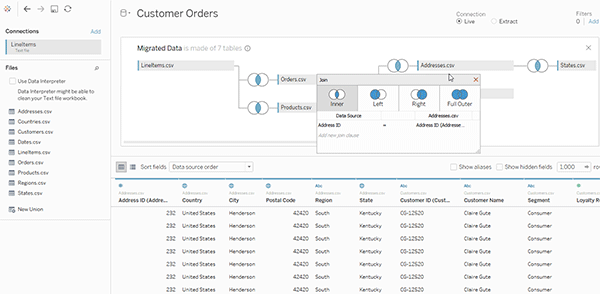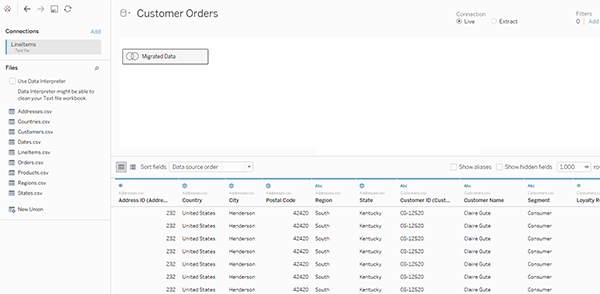
برای مشاهده جداول فیزیکی که یک جدول منطقی واحد را تشکیل میدهند، روی آن جدول منطقی دوبار کلیک کنید تا در لایه فیزیکی باز شود. جداول فیزیکی زیرین آن، از جمله joinها و unionها را مشاهده خواهید کرد.
پرسیدن سوالات در چندین جدول مرتبط
تحلیل مجموعهها: دستهبندی مقادیر بدون تطابق
بسیاری از سوالات تحلیلی نیاز به دستهبندی رکوردها بر اساس وجود یا عدم وجود آنها در جدول دیگر دارند.
برای مثال:
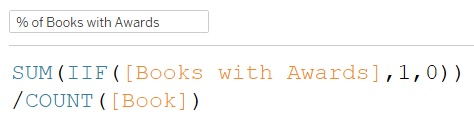
- چه درصدی از کتابها دارای جایزه هستند؟
- از میان کتابهای دارای جایزه، چه درصدی هیچ فروشی نداشتهاند؟
بخش اول: چه درصدی از کتابها دارای جایزه هستند؟

صورت کسر: کتابهایی که جایزه دارند
مخرج کسر: همه کتابها
برای محاسبه صورت کسر، نیاز به یک محاسبه بین جدولها (Cross-table Calculation) داریم، در حالی که مخرج کسر را میتوان فقط از جدول Book محاسبه کرد.
یک روش خوب این است که همه محاسبات را در یک جدول متمرکز کنید تا راحتتر بتوان سطح جزئیات و مجموعه رکوردهای درگیر در محاسبه را درک کرد.
برای یافتن کتابهایی که جایزه دارند، در اصل میخواهیم هر ردیف در جدول Book را با مقدار True یا False علامتگذاری کنیم تا مشخص شود آیا آن کتاب در جدول Award وجود دارد یا نه.
این کار را میتوان با استفاده از مجموعهها (Sets) یا عبارت سطح جزئیات (LoD Expression) انجام داد.
عبارت LoD زیر را اینگونه تصور کنید:
جدول Book تعداد رکوردهای تطبیقیافته از جدول Awards را دریافت میکند.
اگر تعداد آنها یک یا بیشتر باشد، یعنی آن کتاب جایزه دارد.

از آنجایی که عبارت LoD فوق متعلق به جدول Book است، طبق نکات و ترفندهایی که در پست قبلی نشان داده شد، “1” نشان دهنده یک کتاب است.
بخش دوم: چند درصد از کتابهای برنده جایزه، فروش نرفتهاند؟
صورت کسر: کتابهایی که جوایزی دریافت کردهاند و فروش نداشتهاند. مخرج کسر: کتابهایی که جوایزی دریافت کردهاند. برای یافتن کتابهایی که فروش نداشتهاند، میتوانیم تعداد فروشها را در جدول کتابها وارد کنیم تا یک پرچم درست/غلط برای هر کتاب ایجاد شود. وقتی تعداد فروش هر کتاب ۰ باشد، کتاب هیچ فروشی ندارد.

توجه داشته باشید که چون جدول فروش (Sales) از طریق جدول نسخهها (Edition) به جدول کتابها (Book) مرتبط است، این ارتباط بهتنهایی نمیتواند دلیل عدم فروش یک کتاب را مشخص کند. ممکن است کتاب منتشر نشده باشد، یا اینکه منتشر شده ولی فروخته نشده باشد.
با این حال، کتابهای منتشر نشده نمیتوانند جایزه دریافت کنند، بنابراین میتوان فرض کرد که کتابهایی که جایزه دارند ولی فروش ندارند، در واقع منتشر شدهاند اما فروخته نشدهاند.
درک درست از روابط بین جدولها در دادههای شما برای نگارش دقیق محاسبات و تفسیر صحیح نتایج بسیار مهم است.
با ترکیب این عبارت سطح جزئیات (LoD Expression) با عبارت قبلی، میتوانیم درصد کتابهایی که جایزه دارند اما فروخته نشدهاند را محاسبه کنیم.

توجه داشته باشید که اگرچه عبارات LoD با جدول خود گروهبندی میشوند، محاسبات تجمعی با هیچ جدولی گروهبندی نمیشوند، زیرا سطح جزئیات آنها فقط زمانی مشخص میشود که در یک تجسم استفاده شوند.
رفع ابهام در پرسشها: معیار، منبع معیار، و بُعد
تحلیل دادهها نیازمند تبدیل پرسشهای تجاری به پرسشهایی بدون ابهام و قابل محاسبه است.
برای مثال، یک پرسش تجاری ممکن است این باشد:
«آیا نظر کارشناسان و عموم مردم درباره اینکه کدام کتابها خوب هستند، یکسان است؟»
ممکن است برای تعیین نظر کارشناسان از جوایز استفاده کنید و برای نظر عموم مردم از امتیازدهیها (Ratings) بهره ببرید.
پرسشی مانند «میانگین امتیازها برای هر جایزه چقدر است؟» ممکن است ترجمهای منطقی از پرسش تجاری به نظر برسد، اما همچنان مبهم است؛ زیرا واژه “امتیازها” میتواند به خود معیار اشاره داشته باشد یا به جدولی که معیار از آن آمده—یعنی منبع معیار.
پرسشی دقیقتر میتواند این باشد:
«میانگین امتیاز برای بررسیهایی که با هر جایزه مرتبط هستند چقدر است؟»
(در این حالت، کتاب نادیده گرفته میشود.)
پرسش جایگزین میتواند این باشد:
«میانگین امتیاز برای کتابهایی که هر جایزه را دریافت کردهاند چقدر است؟»
(در این حالت، تعداد امتیازهای هر کتاب نادیده گرفته میشود.)
این دو پرسش پاسخهای متفاوتی ارائه میدهند:
- پرسش اول همه امتیازها را بهطور مساوی وزندهی میکند. اگر یک کتاب تمام امتیازها را دریافت کرده باشد، آن کتاب بهطور نامتناسبی نمایان خواهد شد.
- پرسش دوم همه کتابها را بهطور مساوی وزندهی میکند، صرفنظر از اینکه هر کتاب چند امتیاز دریافت کرده است.
پرسش اول میانگین ساده است، در حالی که پرسش دوم میانگینِ میانگینها است.
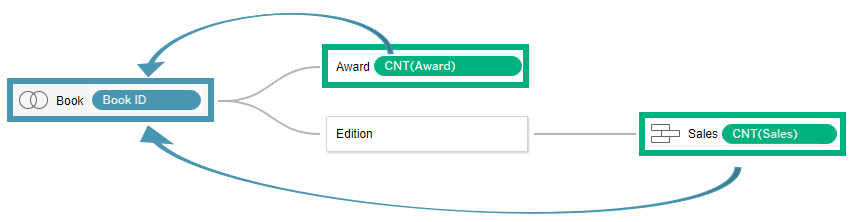
در اینجا یک رابطه چندبهچند بین امتیازها و جوایز وجود دارد، در حالی که بین کتابها و جوایز یک رابطه یکبهچند برقرار است.
درک کاردینالیتی (Cardinality) در دادههای شما میتواند به انتخاب سطح مناسب تجمیع برای پرسش کمک کند.
در نهایت، حتی اگر یک محاسبه از نظر منطقی و ریاضی معتبر باشد، درستی آن فقط با توجه به هدف پرسش قابل ارزیابی است.
میانگین امتیاز برای بررسیهای مرتبط با هر جایزه
از آنجا که معیار امتیاز از جدولی میآید که هر رکورد آن یک بررسی (Review) است، نتیجه این محاسبه با تقسیم میانگین امتیازها بر اساس جوایز بهدست میآید.
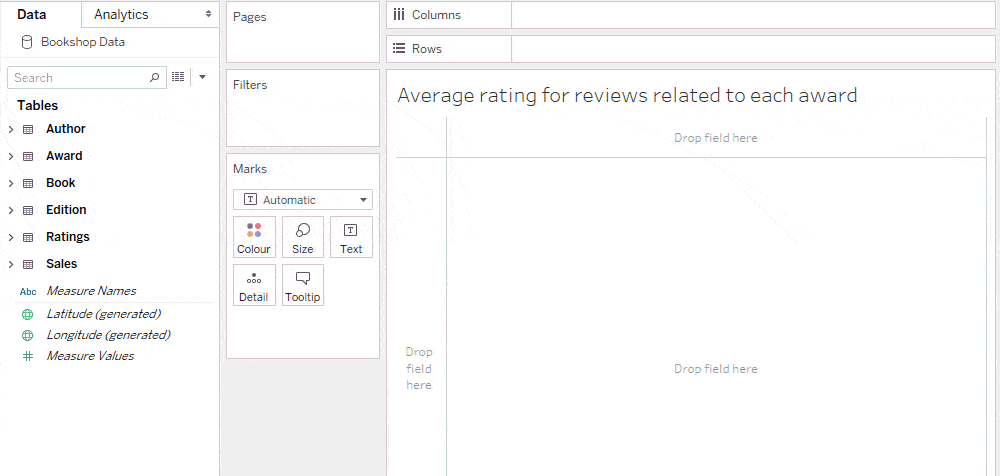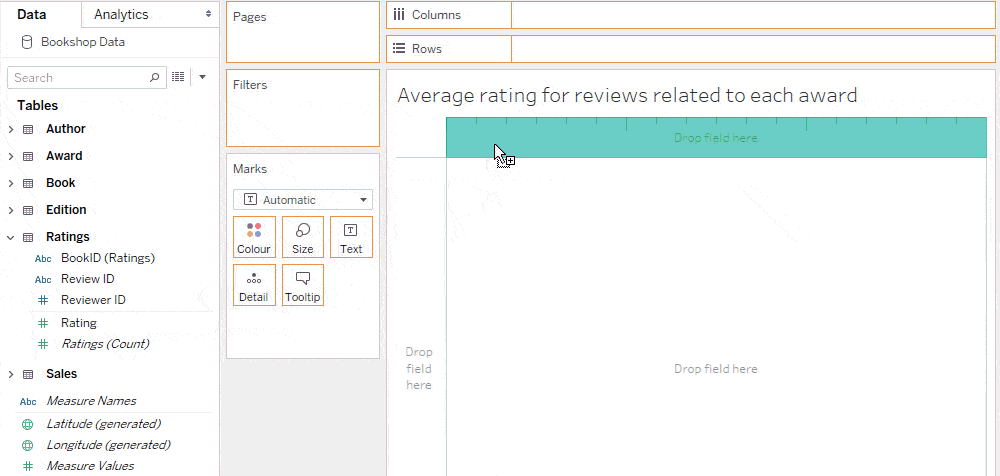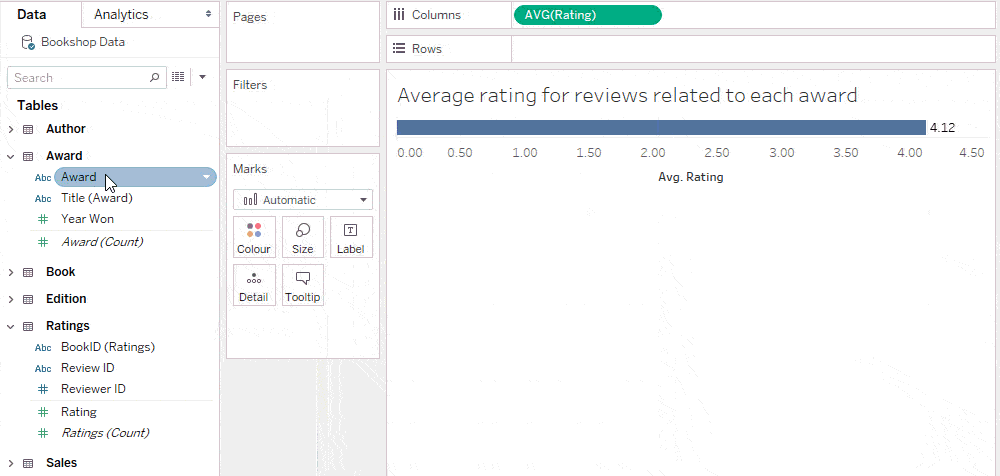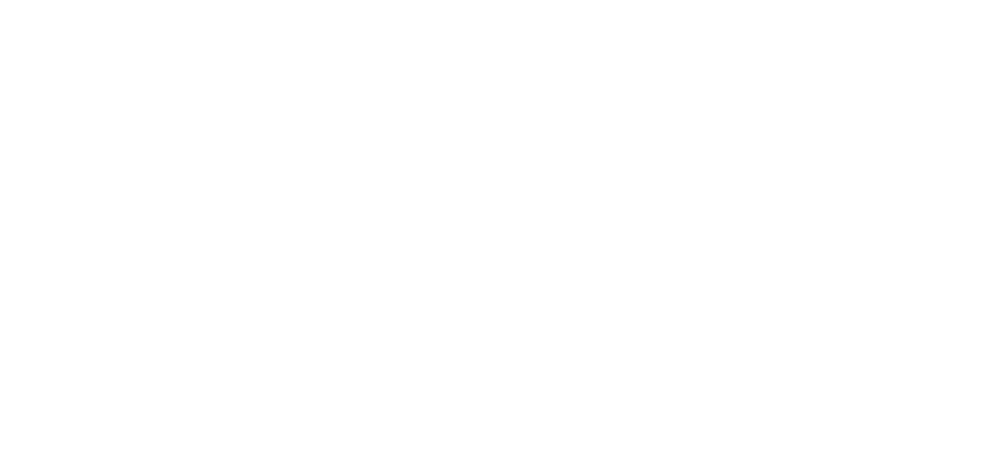
میانگین امتیاز برای کتابهایی که هر جایزه را کسب کردهاند
برای محاسبه این نتیجه، باید میانگین امتیاز را به جدول کتابها منتقل کنیم.
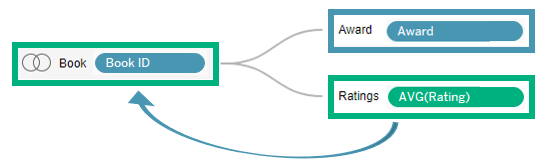
ما میتوانیم این کار را با یک عبارت LoD انجام دهیم که میانگین امتیاز هر کتاب را محاسبه میکند.

منبع این معیار جدید، کتاب است، بنابراین میانگین این محاسبه که بر اساس جایزه تقسیم میشود، پاسخ مورد نظر را میدهد.
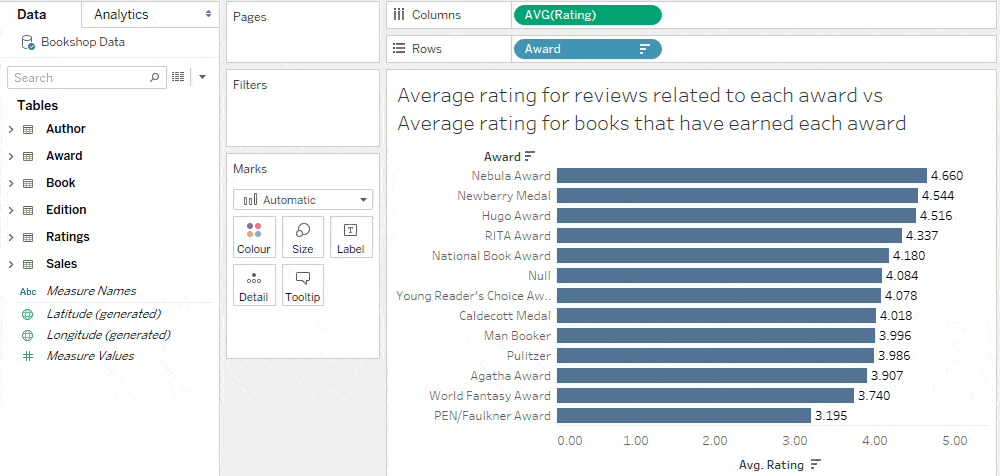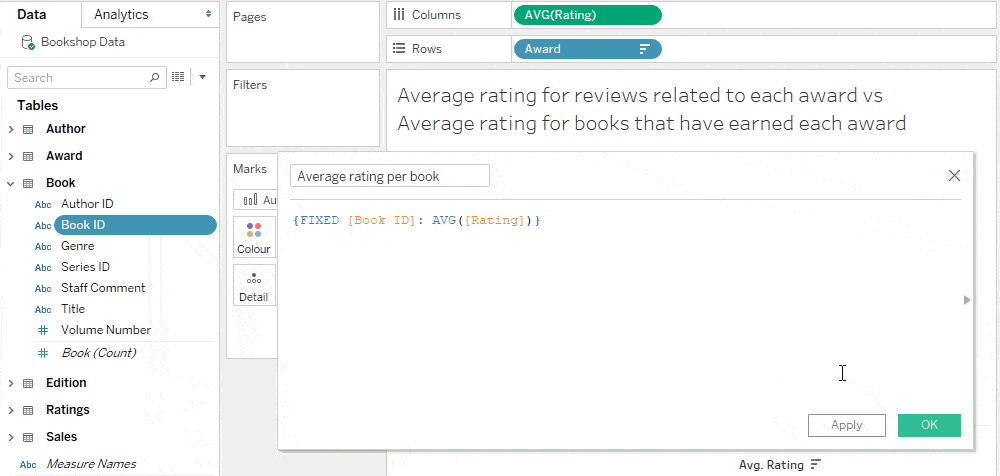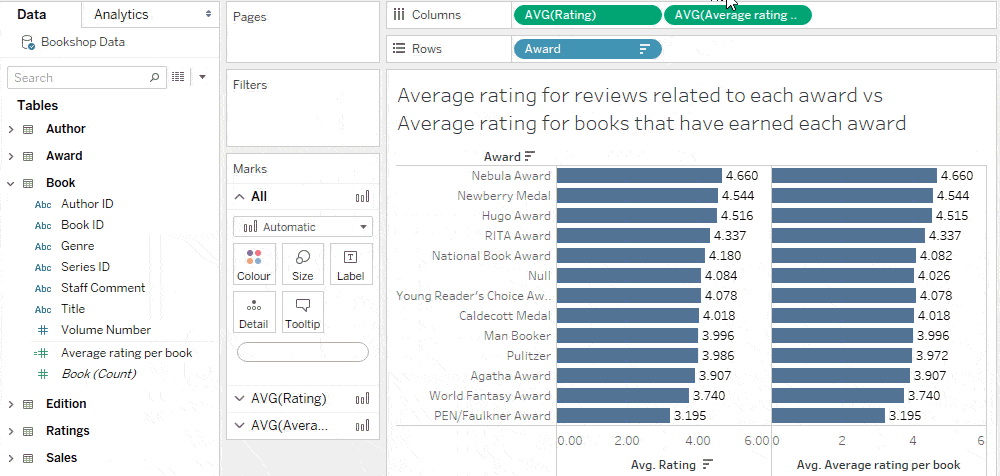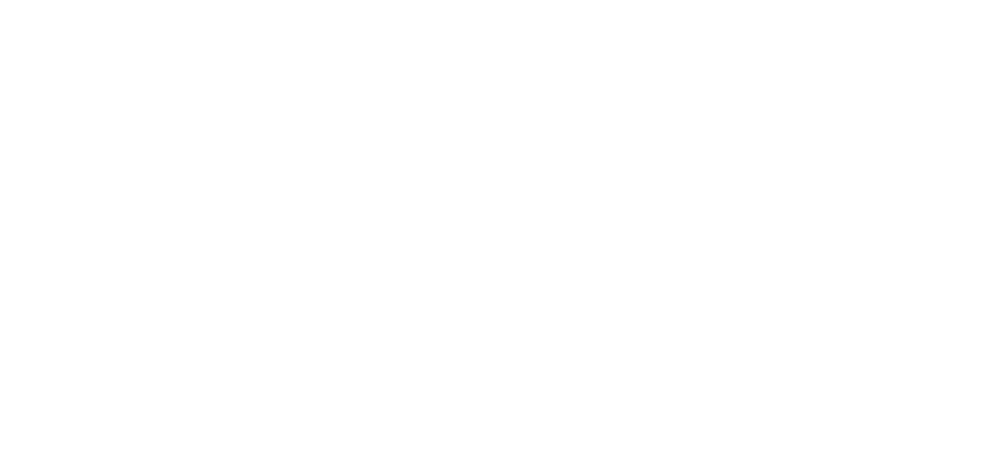
تفسیر نتایج: معیار، منبع معیار، بُعد، و رابطه
در هنگام تفسیر نتایج تحلیل، توجه به موارد زیر بسیار مفید است:
- معیار (Measure): چه چیزی را اندازهگیری میکنید؟
- منبع معیار: این معیار از کدام جدول آمده است؟
- بُعد (Dimension): دادهها بر اساس چه ویژگیهایی دستهبندی شدهاند؟
- رابطه (Relationship): جدولها چگونه به هم مرتبط شدهاند؟
درک روابط بین جدولها بهویژه برای تفسیر سطح جزئیات مقادیر Null بدون تطابق اهمیت زیادی دارد.
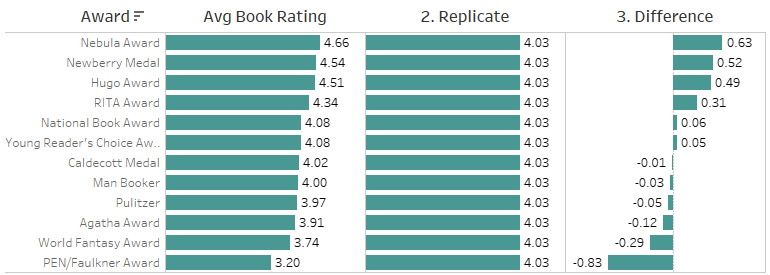
تصویرسازی (Viz) حاصل از تحلیل قبلی نشان میدهد که کارشناسان و عموم مردم اغلب با یکدیگر توافق ندارند.
نیمی از جوایز، میانگین امتیاز کتابهایی که آنها را دریافت کردهاند، کمتر از میانگین امتیاز کتابهای بدون جایزه است.

برای مشاهده میزان تفاوت دیدگاهها، آیا بهتر نیست تفاوت میانگین امتیاز کتابها برای هر جایزه را با میانگین امتیاز کتابهای بدون جایزه مقایسه کنیم؟
محاسبات بین جدولها: انتقال محاسبات سطح ردیف به یک جدول مشترک
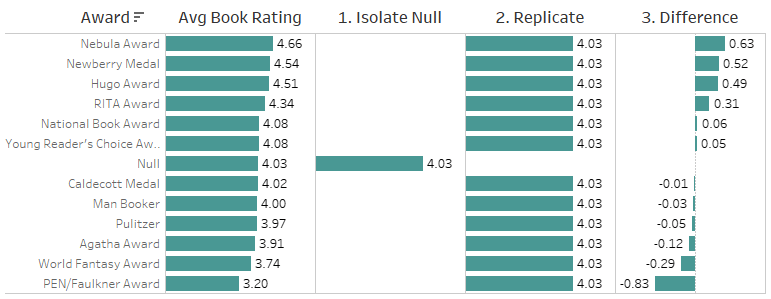
برای محاسبه این تفاوت در میان ردیفهای تجمیعی، سه مرحله لازم است:
- جدا کردن معیار برای مقادیر Null بدون تطابق
ابتدا باید میانگین امتیاز کتابهایی که جایزه ندارند را بهصورت مستقل محاسبه کنیم. - تکرار معیار مربوط به Null در تمام جوایز
سپس این مقدار را بهگونهای در جدول جوایز اعمال کنیم که برای هر جایزه قابل مقایسه باشد. - کم کردن مقدار معیار اصلی از مقدار تکرارشده
در نهایت، مقدار میانگین امتیاز کتابهای بدون جایزه را از میانگین امتیاز کتابهای دارای جایزه کم میکنیم تا اختلاف نظر مشخص شود.
۱. جدا کردن معیار برای مقادیر Null بدون تطابق
در مرحله اول، ممکن است وسوسه شوید که یک محاسبه در سطح ردیف بین جدولها بنویسید که هیچ دادهای برنمیگرداند.

این اتفاق به این دلیل است که محاسبات سطح ردیف بین جدولها از اتصال داخلی (Inner Join) استفاده میکنند، که باعث حذف کتابهایی میشود که جایزه ندارند.
عبارت ISNULL فقط مقادیر گمشده را تشخیص میدهد، نه مقادیر بدون تطابق.
یک روش خوب برای نوشتن محاسبات سطح ردیف بین جدولها این است که همه فیلدهای مرتبط را به یک جدول مشترک منتقل کنید.
دلیل این کار آن است که محاسبات سطح ردیف باعث ایجاد اتصالهایی در سطح ردیف میشوند و یک جدول ضمنی میسازند که با جدولهای موجود در مدل داده شما متفاوت است.
انتقال همه فیلدهای مرتبط به یک جدول قبل از انجام محاسبه، باعث میشود درک سطح جزئیات و مجموعه رکوردهای درگیر در محاسبه آسانتر شود.
محاسبه “میانگین امتیاز برای هر کتاب” در حال حاضر در سطح جزئیات جدول Book قرار دارد.
فقط کافی است عبارت ISNULL(Award) را نیز در همین سطح حل کنیم، یعنی آن را به Book ID متصل کنیم.
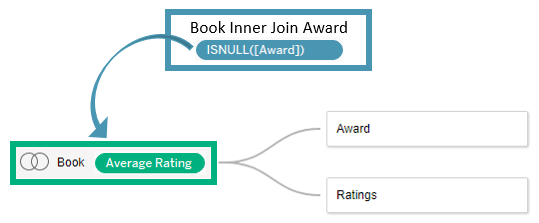
یافتن جوایز پوچِ بیهمتا معادل یافتن مجموعهای از کتابها است که هیچ جایزهای ندارند.
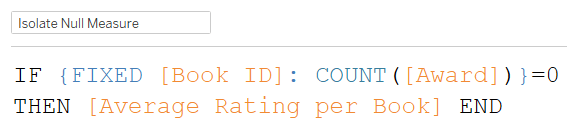
این محاسبه یک مقدار واحد را برمیگرداند که میانگین امتیاز کتابهایی است که هیچ جایزهای دریافت نکردهاند.
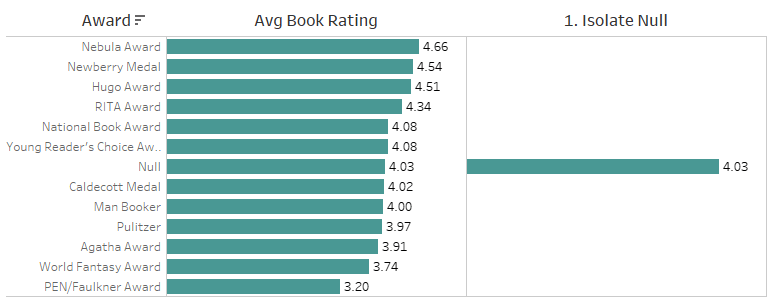
۲. تکرار معیار مربوط به مقدار Null بدون تطابق
برای تکرار مقدار مربوط به کتابهای بدون جایزه در میان همه جوایز، میتوان از یک عبارت سطح جزئیات EXCLUDE (EXCLUDE LoD Expression) استفاده کرد.
عبارت EXCLUDE به شما این امکان را میدهد که یک بُعد خاص (در اینجا Award) را از سطح تجمیع حذف کنید، تا مقدار محاسبهشده (مثلاً میانگین امتیاز کتابهای بدون جایزه) در تمام ردیفهای مربوط به جوایز تکرار شود.
این روش باعث میشود بتوانید مقدار معیار مربوط به کتابهای بدون جایزه را در کنار مقدار معیار مربوط به کتابهای دارای جایزه قرار دهید و در مرحله بعد، تفاوت آنها را محاسبه کنید.

این محاسبه، مقدار محاسبهی معیار پوچیِ ایزوله را برای هر جایزه تکرار میکند – یک گام میانی لازم برای محاسبهی تفاوتها.
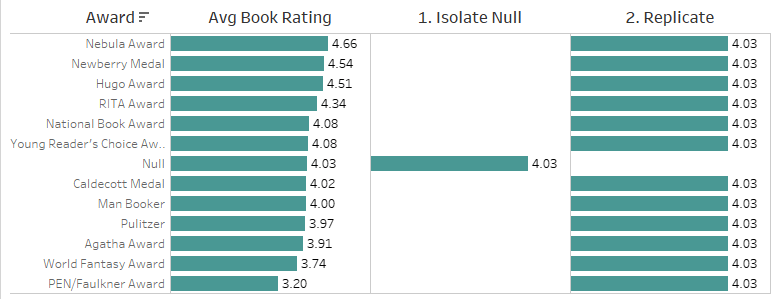
۳. محاسبه تفاوت
مرحله نهایی اکنون یک محاسبه تجمیعی ساده است: کافی است مقدار میانگین امتیاز کتابهای دارای جایزه را از مقدار میانگین امتیاز کتابهای بدون جایزه کم کنیم.
نکته مهم این است که توصیه برای انتقال محاسبات به یک جدول مشترک، صرفاً برای محاسبات در سطح ردیف (Row-Level Calculations) کاربرد دارد.
در مورد محاسبات تجمیعی (Aggregate Calculations)، معمولاً بهتر است آنها را به سطح جزئیات خاصی محدود نکنید تا بتوانند با زمینه تصویرسازی (Viz Context) و فیلترهای اعمالشده تطبیق پیدا کنند و انعطافپذیر باقی بمانند.

این محاسبه، وقتی بر اساس جایزه نمایش داده شود، تفاوت بین میانگین امتیاز برای آن جایزه و میانگین امتیاز برای کتابهایی که جایزهای دریافت نکردهاند (فیلد تکرار) را نشان میدهد. پنهان کردن مقدار null نتیجه مطلوب را میدهد. اگر null را حذف کنید، فیلد تکرار (و در نتیجه تفاوت) null میشود زیرا دادههای مربوطه فیلتر میشوند. پنهان کردن به ما این امکان را میدهد که دادهها را در محاسبات بگنجانیم، در حالی که آنها را از viz حذف میکنیم.
سوراخ خرگوش (Down the rabbit hole)
ممکن است بپرسید چرا عبارت LoD (سطح جزئیات) EXCLUDE (مستثنی کردن) معیار (measure) را برای سطر null (تهی) نامطابق (unmatched) تکرار نکرد.
پاسخ مستند این است که عبارتهای LoD در سطح سطر ارزیابی میشوند و محاسبات در سطح سطر در سراسر جداول از اتصال داخلی (inner joins) استفاده میکنند. شاید با خود فکر کنید: «این مسخره است، چرا از اتصال خارجی (outer joins) استفاده نمیکنید؟»
وظیفه شماره ۱ در شرح شغل مدیریت محصول، عذرخواهی از مشتری است – و اکنون همان لحظه است. ساخت یک محصول مستلزم پاسخدهی نامتناسب به این سؤال است: «بدترین گزینه کدام است؟»
با وجود «روابط» (relationships)، این سؤال بارها در زمینه اینکه با مقادیر null چه باید کرد، مطرح شد.
دو نوع متمایز از مقادیر null وجود دارد:
- مقادیر گمشده (Missing values): یک سطر وجود دارد، اما یک مقدار برای آن ستون غایب است.
- مقادیر نامطابق (Unmatched values): یک اتصال (join) با جدول دیگر، یک سطر را به وجود میآورد.
این دو نوع null، معانی بسیار متفاوتی دارند. گروهبندی هر دو بهعنوان «دادههای کثیفی که همه ما برای حذف آنها یک واکنش ناخودآگاه پیدا کردهایم چون فکر کردن به آنها سخت است»، کار اشتباهی است.
یکی از تصمیمهایی که باید میگرفتیم این بود که آیا محاسبات در سطح سطر در سراسر جداول قبل از اینکه جداول به هم متصل شوند اتفاق میافتد یا بعد از آن. اگر نرمافزار میتوانست همیشه به صورت جادویی ترتیبی را که میخواستید انتخاب کند عالی میشد، اما متأسفانه رایانهها تحت دستورالعملهای مبهم منفجر میشوند.
ما تصمیم گرفتیم محاسبات در سطح سطر را قبل از اتصال (join) اجرا کنیم تا همچنان بتوانید هنگام استفاده از تابع ISNULL (آیا تهی است) بین مقادیر گمشده و مقادیر نامطابق تمایز قائل شوید. این امر گاهی اوقات میتواند نتایج غیرمنتظرهای به همراه داشته باشد، مانند جدول زیر. با یک محاسبه LoD که تعداد جوایز هر کتاب را میشمارد، میتوانید null نامطابق را شناسایی کنید.
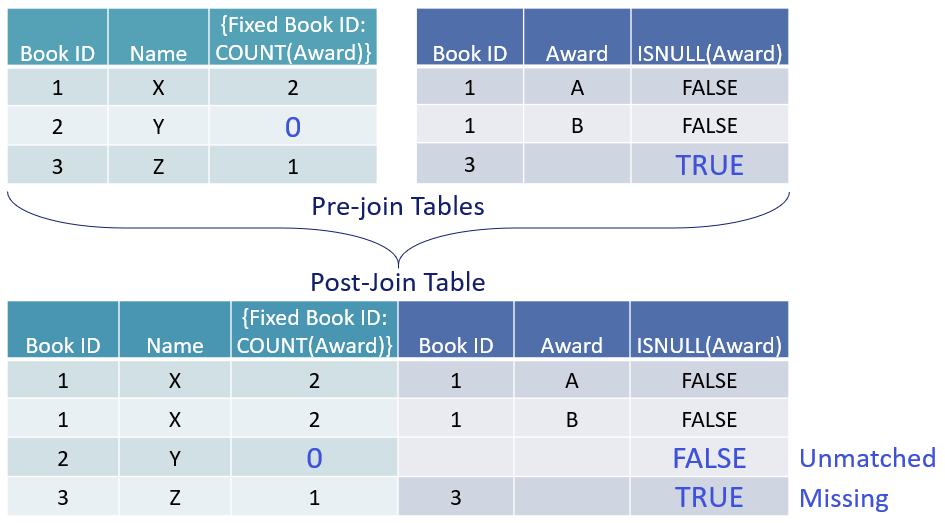
چرا LoD نتوانست null نامطابق را نجات دهد؟
اگر محاسبات سطح سطر بعد از اتصال (join) اتفاق میافتَت، تنها راه تمایز قائل شدن بین مقادیر گمشده و مقادیر نامطابق این بود که آنها را از قبل در دادههای خود محاسبه کنید؛ که نیازمند SQL سفارشی یا کپیهای تکراری از دادههایتان بود. ما فکر کردیم که این گزینه بسیار بدتر است.
بنابراین، یکی از عوارض جانبی انتخاب کمتر بدترین گزینه این است که باید بهجای توابع ISNULL، از LoDها برای شناسایی مقادیر نامطابق استفاده شود (همانطور که در تصویر بالا نشان داده شده است).
شاید هنوز بپرسید چرا پس در عبارت LoD EXCLUDE، معیار (measure) برای null نامطابق تکرار نشد، درحالیکه LoDها فرضاً ناجی nullها هستند؟
پاسخ اینجاست:
- توانایی LoDها: LoDها فقط میتوانند nullهای نامطابقِ سرگردانی را نجات دهند که میتوانند به جدولِ قبل از اتصال (pre-join table) کشیده شوند (یکی از مستطیلها در تب داده).
- محدودیت LoDها: LoDها در برابر nullهای نامطابق که در جداولِ بعد از اتصال (post-join tables) احضار میشوند، بیدفاع هستند. این جداول فقط در فضای مجازی وجود دارند؛ آنها صرفاً سایهای از یک جدول غیرموجود هستند.
گزارش بصری (viz) آخر ما بسیار واقعی به نظر میرسد، اما فقط سایهای از یک جدول غیرموجود است. اگر چشمهای خود را نمیغلتانید یا سریعاً به دنبال دکمهی فرار نیستید – تبریک میگویم! شما از فرآیند ارزیابی مشاور مشتری جان سالم به در بردهاید. با تیم PM مدلسازی و محاسبات داده از طریق dmcpmteam (در) tableau (دات-کام) در تماس باشید! از این نام مستعار غیرشخصی نترسید – ما گروه کوچکی متشکل از چهار نفر هستیم و دوست داریم در مورد نیازهای شما از Tableau بیشتر بدانیم.
خلاصه
«روابط» (Relationships)، ظرافتهایی را در دادههای شما آشکار میسازند که قبلاً نادیده گرفتن آنها آسان بود، مانند:
- سطح جزئیات معیارهای شما.
- مقادیر نامطابق در سراسر جداول.
- کارایی (Cardinality) بین جداول.
- مسیر دستیابی به یک جدول از جدول دیگر.
تجزیهوتحلیل مؤثر دادهها، مسئلهی پرسیدن سؤالات خوب و دقیق و تفسیر نتایج فراتر از نام فیلدها است. اگر به نتایجی دست یافتید که انتظار نداشتید، قبل از جستجو در فایلهای لاگ SQL برای یافتن توضیح، مطمئن شوید که میتوانید روابط موجود در دادههای خود و سؤال خود را به زبان ساده شرح دهید.
برای خرید لایسنس نرم افزار Tableau ، میتوانید از خدمات ما استفاده نموده و درخواست خود را از طریق فرم زیر ثبت نمایید.



{kind=link}
بدون دیدگاه