
توابع تجمیعی Aggregate Function در Tableau
توابع تجمیعی Aggregate Function به شما امکان میدهند جزئیات دادههای خود را خلاصه یا تغییر دهید.
برای مثال، ممکن است بخواهید دقیقاً بدانید که فروشگاه شما در یک سال خاص چند سفارش داشته است. میتوانید از تابع COUNTD برای محاسبه تعداد دقیق سفارشهای منحصر به فرد شرکت خود استفاده کنید و سپس نمودار را بر اساس سال تقسیمبندی کنید.
محاسبه ممکن است چیزی شبیه به این باشد:
COUNTD(Order ID)
این ویژوال ممکن است چیزی شبیه به این باشد:
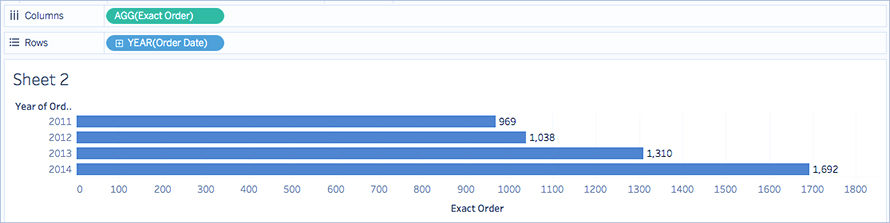
توابع تجمیعی موجود در Tableau
جمعبندیها و محاسبات ممیز شناور: نتایج برخی از تجمیعها ممکن است همیشه دقیقاً مطابق انتظار نباشد. به عنوان مثال، ممکن است متوجه شوید که تابع SUM مقداری مانند -1.42e-14 را برای ستونی از اعداد برمیگرداند که میدانید مجموع آنها باید دقیقاً برابر با 0 باشد. این اتفاق میافتد زیرا استاندارد ممیز شناور موسسه مهندسان برق و الکترونیک (IEEE) 754 الزام میکند که اعداد در قالب دودویی ذخیره شوند، به این معنی که اعداد گاهی اوقات با سطوح دقت بسیار دقیقی گرد میشوند. میتوانید این حواسپرتی بالقوه را با استفاده از تابع ROUND یا با قالببندی عدد برای نمایش ارقام اعشاری کمتر، از بین ببرید.
ATTR
| Syntax | ATTR(expression) |
| Definition | اگر عبارت برای همه ردیفها یک مقدار داشته باشد، مقدار آن را برمیگرداند. در غیر این صورت یک ستاره برمیگرداند. مقادیر Null نادیده گرفته میشوند. |
AVG
| Syntax | AVG(expression) |
| Definition | میانگین تمام مقادیر موجود در عبارت را برمیگرداند. مقادیر Null نادیده گرفته میشوند. |
| Notes | AVG فقط با فیلدهای عددی قابل استفاده است. |
COLLECT
| Syntax | COLLECT(spatial) |
| Definition | یک محاسبهی کلی که مقادیر موجود در فیلد آرگومان را ترکیب میکند. مقادیر Null نادیده گرفته میشوند. |
| Notes | COLLECT فقط با فیلدهای مکانی قابل استفاده است. |
CORR
| Syntax | CORR(expression1, expression2) |
| Output | Number from -1 to 1 |
| Definition | ضریب همبستگی پیرسون دو عبارت را برمیگرداند. |
| Notes | همبستگی پیرسون رابطه خطی بین دو متغیر را اندازهگیری میکند. نتایج از -1 تا +1 متغیر است، که در آن 1 نشان دهنده یک رابطه خطی مثبت دقیق، 0 نشان دهنده عدم وجود رابطه خطی بین واریانس و -1 یک رابطه منفی دقیق است.
مجذور نتیجه CORR معادل مقدار R-Squared برای یک مدل خط روند خطی است. استفاده با عبارات LOD در محدوده جدول: شما میتوانید از CORR برای تجسم همبستگی در یک پراکندگی تفکیکی با استفاده از یک عبارت سطح جزئیات در محدوده جدول استفاده کنید (لینک در یک پنجره جدید باز میشود). به عنوان مثال: {CORR(فروش، سود)} با یک عبارت سطح جزئیات، همبستگی روی تمام ردیفها اجرا میشود. اگر از فرمولی مانند CORR(فروش، سود) (بدون براکتهای اطراف برای تبدیل آن به یک عبارت سطح جزئیات) استفاده کنید، نمای همبستگی هر نقطه جداگانه در نمودار پراکندگی را با هر نقطه دیگر نشان میدهد که تعریف نشده است. |
| Database limitations | CORR با منابع داده زیر در دسترس است: Tableau data extracts، Cloudera Hive، EXASolution، Firebird (نسخه ۳.۰ و بالاتر)، Google BigQuery، Hortonworks Hadoop Hive، IBM PDA (Netezza)، Oracle، PostgreSQL، Presto، SybaseIQ، Teradata، Vertica.
برای سایر منابع داده، استخراج دادهها یا استفاده از WINDOW_CORR را در نظر بگیرید. |
COUNT
| Syntax | COUNT(expression) |
| Definition | تعداد آیتمها را برمیگرداند. مقادیر تهی (null) شمرده نمیشوند. |
COUNTD
| Syntax | COUNTD(expression) |
| Definition | تعداد اقلام متمایز در یک گروه را برمیگرداند. مقادیر تهی (null) شمرده نمیشوند. |
COVAR
| Syntax | COVAR(expression1, expression2) |
| Definition | کوواریانس نمونه دو عبارت را برمیگرداند. |
| Notes | کوواریانس، چگونگی تغییر دو متغیر با هم را کمّی میکند. کوواریانس مثبت نشان میدهد که متغیرها تمایل دارند در یک جهت حرکت کنند، مانند زمانی که مقادیر بزرگتر یک متغیر به طور متوسط مطابق با مقادیر بزرگتر متغیر دیگر هستند. کوواریانس نمونه از تعداد نقاط داده غیر تهی n – 1 برای نرمالسازی محاسبه کوواریانس استفاده میکند، نه n که توسط کوواریانس جمعیت (موجود با تابع COVARP) استفاده میشود. کوواریانس نمونه زمانی انتخاب مناسبی است که دادهها یک نمونه تصادفی باشند که برای تخمین کوواریانس برای یک جمعیت بزرگتر استفاده میشوند.
اگر <expression1> و <expression2> یکسان باشند، به عنوان مثال COVAR([profit], [profit])، COVAR مقداری را برمیگرداند که نشان میدهد مقادیر چقدر گسترده توزیع شدهاند. مقدار COVAR(X, X) معادل مقدار VAR(X) و همچنین مقدار STDEV(X)^2 است. |
| Database limitations | COVAR با منابع داده زیر در دسترس است: Tableau data extracts، Cloudera Hive، EXASolution، Firebird (نسخه ۳.۰ و بالاتر)، Google BigQuery، Hortonworks Hadoop Hive، IBM PDA (Netezza)، Oracle، PostgreSQL، Presto، SybaseIQ، Teradata، Vertica.
برای سایر منابع داده، استخراج دادهها یا استفاده از WINDOW_COVAR را در نظر بگیرید. |
COVARP
| Syntax | COVARP(expression 1, expression2) |
| Definition | کوواریانس جمعیت دو عبارت را برمیگرداند. |
| Notes | کوواریانس، چگونگی تغییر دو متغیر با هم را کمّی میکند. کوواریانس مثبت نشان میدهد که متغیرها تمایل دارند در یک جهت حرکت کنند، مانند زمانی که مقادیر بزرگتر یک متغیر به طور متوسط مطابق با مقادیر بزرگتر متغیر دیگر هستند. کوواریانس جمعیت، کوواریانس نمونه ضربدر (n-1)/n است، که در آن n تعداد کل نقاط داده غیر تهی است. کوواریانس جمعیت زمانی انتخاب مناسبی است که برای همه موارد مورد نظر داده موجود باشد، برخلاف زمانی که فقط یک زیرمجموعه تصادفی از موارد وجود دارد، که در این صورت کوواریانس نمونه (با تابع COVAR) مناسب است.
اگر <expression1> و <expression2> یکسان باشند، به عنوان مثال COVARP([profit], [profit])، COVARP مقداری را برمیگرداند که نشان میدهد مقادیر چقدر گسترده توزیع شدهاند. توجه: مقدار COVARP(X, X) معادل مقدار VARP(X) و همچنین مقدار STDEVP(X)^2 است. |
| Database limitations | COVARP با منابع داده زیر در دسترس است: Tableau data extracts، Cloudera Hive، EXASolution، Firebird (نسخه ۳.۰ و بالاتر)، Google BigQuery، Hortonworks Hadoop Hive، IBM PDA (Netezza)، Oracle، PostgreSQL، Presto، SybaseIQ، Teradata، Vertica
برای سایر منابع داده، استخراج دادهها یا استفاده از WINDOW_COVAR را در نظر بگیرید. |
| Syntax | MAX(expression) or MAX(expr1, expr2) |
| Output | Same data type as the argument, or NULL if any part of the argument is null. |
| Definition | حداکثر مقدار از بین دو آرگومان را برمیگرداند، که باید از یک نوع داده باشند.
MAX همچنین میتواند به عنوان یک تجمیع برای یک فیلد واحد اعمال شود. |
| Example |
MAX(4,7) = 7 MAX(#3/25/1986#, #2/20/2021#) = #2/20/2021# MAX([Name]) = "Zander" |
| Notes | برای رشتهها strings
MAX معمولاً مقداری است که به ترتیب حروف الفبا در آخرین ردیف قرار میگیرد. برای منابع داده پایگاه داده، مقدار رشته MAX بالاترین مقدار در ترتیب مرتبسازی تعریف شده توسط پایگاه داده برای آن ستون است. برای تاریخها dates برای تاریخها، MAX جدیدترین تاریخ است. اگر MAX یک تابع تجمیعی باشد، نتیجه سلسله مراتب تاریخ نخواهد داشت. اگر MAX یک مقایسه باشد، نتیجه سلسله مراتب تاریخ را حفظ خواهد کرد. به عنوان یک تابع تجمیعی MAX(expression) یک تابع تجمیعی است و یک نتیجه تجمیعی واحد را برمیگرداند. این به صورت AGG(expression) در عبارت زیر نمایش داده میشود. به عنوان یک مقایسه MAX(expr1, expr2) دو مقدار را مقایسه میکند و یک مقدار در سطح ردیف را برمیگرداند. |
MEDIAN
| Syntax | MEDIAN(expression) |
| Definition | میانه یک عبارت را در تمام رکوردها برمیگرداند. مقادیر تهی نادیده گرفته میشوند. |
| Notes | تابع MEDIAN فقط با فیلدهای عددی قابل استفاده است. |
| Database limitations | MEDIAN برای منابع داده زیر در دسترس نیست: Access، Amazon Redshift، Cloudera Hadoop، HP Vertica، IBM DB2، IBM PDA (Netezza)، Microsoft SQL Server، MySQL، SAP HANA، Teradata.
برای سایر انواع منابع داده، میتوانید دادههای خود را در یک فایل استخراج کنید تا از این تابع استفاده کنید. |
| Syntax | MIN(expression) or MIN(expr1, expr2) |
| Output | Same data type as the argument, or NULL if any part of the argument is null. |
| Definition | حداقل مقدار دو آرگومان را برمیگرداند، که باید از یک نوع داده باشند.
MIN همچنین میتواند به عنوان یک تجمیع برای یک فیلد واحد اعمال شود. |
| Example |
MIN(4,7) = 4 MIN(#3/25/1986#, #2/20/2021#) = #3/25/1986# MIN([Name]) = "Abebi" |
| Notes | برای رشتهها strings
MIN معمولاً مقداری است که به ترتیب حروف الفبا در ابتدا قرار میگیرد. برای منابع داده پایگاه داده، مقدار رشته MIN در ترتیب مرتبسازی تعریف شده توسط پایگاه داده برای آن ستون، کمترین مقدار را دارد. برای تاریخها برای تاریخها، MIN اولین تاریخ است. اگر MIN یک تابع تجمیعی باشد، نتیجه سلسله مراتب تاریخ نخواهد داشت. اگر MIN یک تابع مقایسهای باشد، نتیجه سلسله مراتب تاریخ را حفظ خواهد کرد. به عنوان یک تابع تجمیعی MIN(expression) یک تابع تجمیعی است و یک نتیجه تجمیعی واحد را برمیگرداند. این به صورت AGG(expression) در عبارت زیر نمایش داده میشود. به عنوان یک مقایسه MIN(expr1, expr2) دو مقدار را مقایسه میکند و یک مقدار در سطح ردیف را برمیگرداند.l |
PERCENTILE
| Syntax | PERCENTILE(expression, number) |
| Definition | مقدار صدک را از عبارت داده شده مربوط به <number> مشخص شده برمیگرداند. <number> باید بین 0 و 1 (شامل) باشد و باید یک ثابت عددی باشد. |
| Example |
PERCENTILE([Score], 0.9) |
| Database limitations | این تابع برای منابع داده زیر در دسترس است: اتصالات غیر قدیمی مایکروسافت اکسل و فایل متنی، استخراجها و انواع منبع داده فقط استخراجی (به عنوان مثال، Google Analytics، OData یا Salesforce)، منابع داده Sybase IQ 15.1 و بالاتر، منابع داده Oracle 10 و بالاتر، منابع داده Cloudera Hive و Hortonworks Hadoop Hive، منابع داده EXASolution 4.2 و بالاتر.
برای سایر انواع منبع داده، میتوانید دادههای خود را در یک فایل استخراج استخراج کنید تا از این تابع استفاده کنید. |
STDEV
| Syntax | STDEV(expression) |
| Definition | انحراف معیار آماری تمام مقادیر موجود در عبارت داده شده را بر اساس نمونهای از جمعیت برمیگرداند. |
STDEVP
| Syntax | STDEVP(expression) |
| Definition | انحراف معیار آماری تمام مقادیر موجود در عبارت داده شده را بر اساس یک جمعیت بایاس شده برمیگرداند. |
SUM
| Syntax | SUM(expression) |
| Definition | مجموع تمام مقادیر موجود در عبارت را برمیگرداند. مقادیر Null نادیده گرفته میشوند. |
| Notes | تابع SUM فقط با فیلدهای عددی قابل استفاده است. |
VAR
| Syntax | VAR(expression) |
| Definition | واریانس آماری تمام مقادیر موجود در عبارت داده شده را بر اساس نمونهای از جمعیت برمیگرداند. |
VARP
| Syntax | VARP(expression) |
| Definition | واریانس آماری تمام مقادیر موجود در عبارت داده شده را در کل جمعیت برمیگرداند. |
ایجاد یک Aggregate Calculation
برای یادگیری نحوه ایجاد یک محاسبه تجمیعی، مراحل زیر را دنبال کنید.
- در Tableau Desktop، به منبع داده ذخیره شده Sample – Superstore که همراه با Tableau ارائه میشود، متصل شوید.
- به یک worksheet بروید و Analysis > Create Calculated Field را انتخاب کنید.
- در calculation editor که باز میشود، موارد زیر را انجام دهید:
- نام فیلد محاسبهشده را Margin (حاشیه) قرار دهید.
- فرمول زیر را وارد کنید:
IIF(SUM([Sales]) !=0, SUM([Profit])/SUM([Sales]), 0)
توجه داشته باشید میتوانید از مرجع تابع برای یافتن و افزودن توابع تجمعی و سایر توابع (مانند تابع منطقی IIF در این مثال) به فرمول محاسبه استفاده کنید.
-
- پس از اتمام، روی OK کلیک کنید.
محاسبه تجمیع جدید در زیر بخش «Measures» در پنل «Data» ظاهر میشود. درست مانند سایر فیلدهایتان، میتوانید از آن در یک یا چند تجسم استفاده کنید.
توجه: محاسبات تجمیع همیشه «معیار» هستند.
وقتی Margin روی یک قفسه یا کارت در برگه کار قرار میگیرد، نام آن به AGG(Margin) تغییر میکند، که نشان میدهد این یک محاسبه تجمیع است و دیگر نمیتوان آن را تجمیع کرد.
قوانین Aggregate Calculations
قوانینی که برای محاسبات کل اعمال میشوند به شرح زیر هستند:
- برای هیچ محاسبهی تجمعی، نمیتوانید یک مقدار تجمعی و یک مقدار تفکیکی را با هم ترکیب کنید. برای مثال، عبارت SUM(Price)*[Items] معتبر نیست زیرا SUM(Price) تجمعی است و Items اینطور نیست. با این حال، SUM(Price*Items) و SUM(Price)*SUM(Items) هر دو معتبر هستند.
- عبارات ثابت در یک عبارت، بسته به مورد، به عنوان مقادیر تجمیعی یا تفکیکی عمل میکنند. برای مثال:
SUM(Price*7)andSUM(Price)*7are both valid expressions. - همه توابع را میتوان بر اساس مقادیر تجمیعشده ارزیابی کرد. با این حال، آرگومانهای هر تابع دادهشده یا باید تجمیعشده باشند یا همگی تفکیکشده. برای مثال: MAX(SUM(Sales),Profit عبارت معتبری نیست زیرا فروش تجمیع میشود و سود نه. با این حال، MAX(SUM(Sales),SUM(Profit)) یک عبارت معتبر است.
- نتیجه یک محاسبه کلی همیشه یک معیار است. این شامل عباراتی مانند ATTR(Dimension) یا MIN(Dimension) میشود.
- مانند تجمیعهای از پیش تعریف شده، محاسبات کلی برای جمع کل به درستی محاسبه میشوند.
برای خرید لایسنس نرم افزار Tableau ، میتوانید از خدمات ما استفاده نموده و درخواست خود را از طریق فرم زیر ثبت نمایید.



{kind=link}
بدون دیدگاه