
تعیین ساختار داده ها برای تحلیل در Tableau
Applies to: Tableau Desktop, Tableau Prep, Tableau Public
مفاهیم خاصی وجود دارند که برای درک آمادهسازی دادهها و نحوه ساختاردهی دادهها برای تجزیه و تحلیل، اساسی هستند. دادهها میتوانند در قالبهای بسیار متنوعی تولید، ثبت و ذخیره شوند، اما وقتی صحبت از تجزیه و تحلیل میشود، همه قالبهای داده یکسان نیستند.
آمادهسازی دادهها فرآیندی است که در آن دادههای قالببندی شده به خوبی در یک جدول یا چندین جدول مرتبط قرار میگیرند تا بتوان آنها را در Tableau تجزیه و تحلیل کرد. این شامل ساختار، یعنی ردیفها و ستونها، و همچنین جنبههای پاکیزگی دادهها، مانند انواع دادههای صحیح و مقادیر صحیح دادهها میشود.
چگونه ساختار بر تحلیل تأثیر میگذارد
ساختار دادههای شما ممکن است چیزی نباشد که بتوانید آن را کنترل کنید. بقیه این مبحث فرض میکند که شما به دادههای خام و ابزارهای مورد نیاز برای شکلدهی به آن، مانند Tableau Prep Builder، دسترسی دارید. با این حال، ممکن است موقعیتهایی وجود داشته باشد که نتوانید دادههای خود را به دلخواه تغییر جهت دهید یا تجمیع کنید.
اغلب هنوز هم میتوان تحلیل را انجام داد، اما ممکن است لازم باشد محاسبات یا نحوه برخورد خود با دادهها را تغییر دهید. برای مثالی از نحوه انجام همان تحلیل با ساختارهای داده مختلف، به Tableau Prep Day in the Life Scenarios: Analysis with the Second Date in Tableau Desktop مراجعه کنید (لینک در پنجره جدید باز میشود). اما اگر بتوانید ساختار داده را بهینه کنید، احتمالاً تحلیل شما بسیار آسانتر خواهد شد.
ساختار داده ها در Tableau
Tableau Desktop با دادههایی که در جداول با فرمت مانند صفحه گسترده هستند، بهترین عملکرد را دارد. یعنی دادههایی که در ردیفها و ستونها ذخیره میشوند و سرستونها در ردیف اول قرار دارند. بنابراین چه چیزی باید ردیف یا ستون باشد؟
ردیف چیست؟
یک ردیف یا رکورد میتواند هر چیزی باشد، از اطلاعات مربوط به یک تراکنش در یک فروشگاه خردهفروشی گرفته تا اندازهگیریهای آب و هوایی در یک مکان خاص، یا آمار مربوط به یک پست در رسانههای اجتماعی.
دانستن اینکه یک رکورد (ردیف) در دادهها نشان دهنده چیست، مهم است. این به معنای جزئیات دادهها است.
بهترین روش این است که یک شناسه منحصر به فرد (UID) داشته باشید، مقداری که هر ردیف را به عنوان یک قطعه داده منحصر به فرد مشخص میکند. آن را مانند شماره تأمین اجتماعی یا URL هر رکورد در نظر بگیرید. در Superstore، این شناسه ردیف (Row ID) خواهد بود. توجه داشته باشید که همه مجموعه دادهها UID ندارند، اما داشتن آن ضرری ندارد.
سعی کنید مطمئن شوید که میتوانید به سوال “یک ردیف در مجموعه دادهها نشان دهنده چیست؟” پاسخ دهید. این همان پاسخ به “فیلد TableName(Count) نشان دهنده چیست؟” است. اگر نمیتوانید آن را بیان کنید، ممکن است دادهها برای تجزیه و تحلیل به خوبی ساختار نیافته باشند.
تجمیع و دانهبندی
مفهومی مرتبط با آنچه یک ردیف را تشکیل میدهد، ایده تجمیع و دانهبندی است که دو سر یک طیف هستند.
تجمیع (Aggregation)
به چگونگی تجمیع چندین مقدار داده در یک مقدار واحد اشاره دارد، مانند شمارش تمام جستجوهای گوگل برای ادویه کدو تنبل یا گرفتن میانگین تمام قرائتهای دما در اطراف سیاتل در یک روز معین.
به طور پیشفرض، معیارها در Tableau همیشه تجمیع میشوند. تجمیع پیشفرض SUM است. میتوانید تجمیع را به گزینههایی مانند میانگین، میانه، تعداد متمایز، حداقل و غیره تغییر دهید.
دانهبندی (Granularity)
به میزان جزئیات دادهها اشاره دارد. یک ردیف یا رکورد در مجموعه دادهها چه چیزی را نشان میدهد؟ یک فرد مبتلا به مالاریا؟ کل موارد مالاریا در یک استان برای ماه؟ این همان دانهبندی است.
دانستن دانهبندی دادهها برای کار با عبارات سطح جزئیات (LOD) بسیار مهم است.
درک تجمیع و دانهبندی به دلایل زیادی یک مفهوم حیاتی است؛ این امر بر مواردی مانند یافتن مجموعه دادههای مفید، ساخت تجسم مورد نظر، مرتبط کردن یا اتصال صحیح دادهها و استفاده از عبارات LOD تأثیر میگذارد.
فیلد یا ستون چیست؟
یک ستون از دادهها در یک جدول به عنوان یک فیلد در پنجره دادهها وارد Tableau Desktop میشود، اما اساساً این دو اصطلاح قابل تعویض هستند. (ما اصطلاح ستون را در Tableau Desktop برای استفاده در قفسه ستونها و ردیفها و برای توصیف تجسمهای خاص ذخیره میکنیم.) یک فیلد از دادهها باید شامل مواردی باشد که میتوانند در یک رابطه بزرگتر گروهبندی شوند. خود این موارد، مقادیر یا اعضا نامیده میشوند (فقط ابعاد گسسته شامل اعضا هستند).
مقادیر مجاز در یک فیلد مشخص توسط دامنه فیلد تعیین میشود (به یادداشت زیر مراجعه کنید). به عنوان مثال، یک ستون برای “بخشهای فروشگاه مواد غذایی” ممکن است شامل اعضای “deli” “bakery”، “produce” و غیره باشد، اما شامل “bread” یا “salami” نمیشود زیرا اینها اقلام هستند، نه بخشها. به عبارت دیگر، دامنه فیلد بخش فقط به بخشهای ممکن فروشگاه مواد غذایی محدود میشود.
علاوه بر این، یک مجموعه داده با ساختار خوب، یک ستون برای «فروش» و یک ستون برای «سود» خواهد داشت، نه یک ستون برای «پول»، زیرا سود مفهومی جدا از فروش است.
- دامنه فیلد فروش، مقادیر ≥ 0 خواهد بود، زیرا فروش نمیتواند منفی باشد.
- با این حال، دامنه فیلد سود، همه مقادیر خواهد بود، زیرا سود میتواند منفی باشد.
دامنه همچنین میتواند به معنای مقادیر موجود در دادهها باشد. اگر ستون “بخش فروشگاه مواد غذایی” به اشتباه شامل “سالامی” باشد، طبق این تعریف، آن مقدار در دامنه ستون قرار میگیرد. تعاریف کمی متناقض هستند. یکی مقادیری است که میتوانند یا باید آنجا باشند، دیگری مقادیری است که واقعاً آنجا هستند.
دستهبندی فیلدها در Tableau
هر ستون در جدول دادهها به عنوان یک فیلد وارد Tableau Desktop میشود که در پنجره Data ظاهر میشود. فیلدها در Tableau Desktop باید یا بُعد(Dimensions) یا معیار (Measures) باشند (با یک خط در جداول در پنجره Data از هم جدا شوند) و یا گسسته (Discrete) یا پیوسته (Continuous) باشند (با کد رنگی: فیلدهای آبی گسسته و فیلدهای سبز پیوسته هستند).
Categorizing fields
- ابعاد کیفی هستند، به این معنی که نمیتوان آنها را اندازهگیری کرد، بلکه میتوان آنها را توصیف کرد. ابعاد اغلب چیزهایی مانند شهر یا کشور، رنگ چشم، دسته، نام تیم و غیره هستند. ابعاد معمولاً گسسته هستند.
- معیارها کمی هستند، به این معنی که میتوان آنها را با اعداد اندازهگیری و ثبت کرد. معیارها میتوانند چیزهایی مانند فروش، ارتفاع، کلیکها و غیره باشند. در Tableau Desktop، معیارها به طور خودکار تجمیع میشوند؛ تجمیع پیشفرض SUM است. معیارها معمولاً پیوسته هستند.
- گسسته به معنای جداگانه یا متمایز است. تویوتا با مزدا متمایز است. در Tableau Desktop، مقادیر گسسته به عنوان یک برچسب وارد نما میشوند و آنها پنجرهها را ایجاد میکنند.
- پیوسته به معنای تشکیل یک کل پیوسته و بدون شکست است. 7 با 8 دنبال میشود و سپس فاصله آن تا 9 یکسان است و 7.5 در وسط بین 7 و 8 قرار میگیرد. در Tableau Desktop، مقادیر پیوسته به عنوان یک محور وارد نما میشوند.
- ابعاد معمولاً گسسته هستند و معیارها معمولاً پیوسته هستند. با این حال، همیشه اینطور نیست. تاریخها میتوانند گسسته یا پیوسته باشند.
- تاریخها ابعادی هستند و به طور خودکار به صورت گسسته (به عنوان قطعات تاریخ، مانند “آگوست”، که ماه آگوست را بدون در نظر گرفتن اطلاعات دیگر مانند سال در نظر میگیرد) نمایش داده میشوند. یک خط روند که روی یک جدول زمانی با تاریخهای گسسته اعمال میشود، به چندین خط روند، یکی در هر صفحه، تقسیم میشود.
- در صورت تمایل میتوانیم از تاریخهای پیوسته استفاده کنیم (به عنوان کوتاهسازی تاریخ، مانند “آگوست 2024″، که با “آگوست 2025” متفاوت است). یک خط روند که روی یک جدول زمانی با تاریخهای پیوسته اعمال میشود، یک خط روند واحد برای کل محور تاریخ خواهد داشت.
Tableau Prep
در Tableau Prep، هیچ تمایزی برای ابعاد یا معیارها قائل نشده است. با این حال، درک مفاهیم مربوط به گسسته یا پیوسته، برای مواردی مانند درک نمایش جزئیات در مقابل نمایش خلاصه دادهها در پنل پروفایل، مهم است.
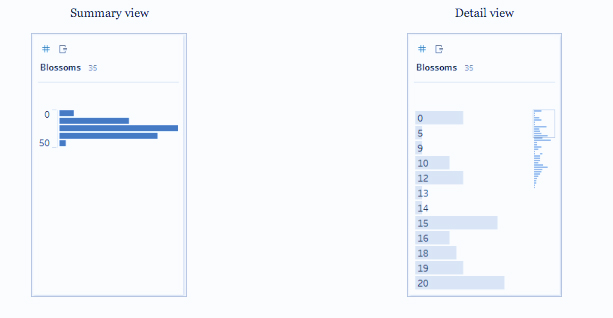
- Detail: نمای جزئیات، هر عنصر دامنه را به عنوان یک برچسب گسسته نشان میدهد و دارای یک نوار پیمایش بصری برای ارائه یک نمای کلی بصری از تمام دادهها است.
- Summary: نمای خلاصه، مقادیر را به صورت دسته بندی شده روی یک محور پیوسته به عنوان یک هیستوگرام نشان میدهد.
ترکیببندی و هیستوگرامها
فیلدی مانند سن یا حقوق، پیوسته در نظر گرفته میشود. بین سن ۳۴ و ۳۵ رابطهای وجود دارد و ۳۴ به همان اندازه از ۳۵ فاصله دارد که ۳۵ از ۳۶. با این حال، وقتی از سن ۱۰ سالگی یا بیشتر عبور میکنیم، معمولاً دیگر نمیگوییم که «۹ و نیم» یا «۷ و ¾» هستیم. ما در حال حاضر سن خود را به صورت دقیق و بر اساس سال ترکیببندی میکنیم. کسی که ۱۲۸۵۰ روز سن دارد، از کسی که ۱۲۷۹۰ روز سن دارد، مسنتر است، اما ما یک خط میکشیم و میگوییم که هر دو ۳۵ سال دارند. به طور مشابه، اغلب از گروهبندی سنی به جای سن واقعی استفاده میشود. قیمت بلیط سینما برای کودکان ممکن است برای کودکان ۱۲ سال و کمتر باشد، یا ممکن است در یک نظرسنجی از شما خواسته شود گروه سنی خود را انتخاب کنید، مانند ۲۰-۲۴، ۲۵-۳۰ و غیره.
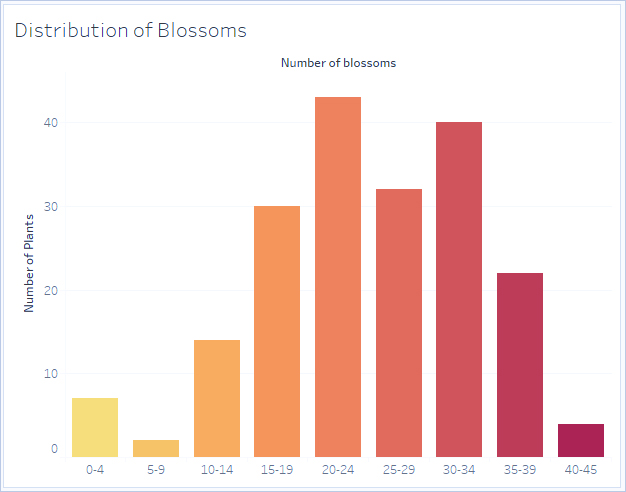
هیستوگرامها برای تجسم توزیع دادههای عددی با استفاده از ترکیببندی استفاده میشوند. یک هیستوگرام شبیه نمودار میلهای است، اما به جای اینکه در هر میله، دستههای گسسته باشند، مستطیلهایی که هیستوگرام را تشکیل میدهند، یک دسته از یک محور پیوسته را در بر میگیرند، مانند محدوده تعداد شکوفهها (0-4، 5-9، 10-14 و غیره). ارتفاع مستطیلها با فراوانی یا تعداد این مقادیر تعیین میشود. در اینجا، محور y تعداد گیاهانی است که در هر دسته قرار میگیرند. هفت گیاه دارای شکوفههای 0-4، دو گیاه دارای شکوفههای 5-9 و 43 گیاه دارای شکوفههای 20-24 هستند.
در Tableau Prep، نمای خلاصه، هیستوگرامی از مقادیر دستهبندی شده است. نمای جزئیات، فراوانی هر مقدار را نشان میدهد و یک نوار اسکرول بصری در کنار آن دارد که توزیع کلی دادهها را نشان میدهد.
توزیعها و دادههای پرت
مشاهده توزیع یک مجموعه داده میتواند به تشخیص دادههای پرت کمک کند.
- توزیع (Distribution): شکل دادهها در یک هیستوگرام، اگرچه این به اندازه دستهها بستگی دارد. امکان مشاهده تمام دادههای شما در یک نمای هیستوگرام میتواند به شناسایی صحیح و کامل بودن دادهها کمک کند. شکل توزیع تنها در صورتی مفید خواهد بود که دادهها را بشناسید و بتوانید تفسیر کنید که آیا توزیع منطقی است یا خیر.
- برای مثال، اگر به مجموعه دادههایی از تعداد خانههای دارای اینترنت پهنباند از سال ۱۹۴۰ تا ۲۰۱۷ نگاه کنیم، انتظار داریم توزیع بسیار نامتوازنی را ببینیم. با این حال، اگر به تعداد خانههای دارای اینترنت پهنباند از ژانویه ۲۰۱۷ تا دسامبر ۲۰۱۷ نگاه کنیم، انتظار توزیع نسبتاً یکنواختی را خواهیم داشت.اگر به مجموعه دادههایی از جستجوهای گوگل برای “لاته کدو حلوایی” نگاه کنیم، انتظار داریم در پاییز یک اوج نسبتاً شدید ببینیم، در حالی که جستجوهای “تبدیل سانتیگراد به فارنهایت” احتمالاً نسبتاً پایدار خواهد بود.
- داده پرت (Outlier): مقداری که در مقایسه با سایر مقادیر، بسیار زیاد است. دادههای پرت ممکن است مقادیر صحیح باشند یا ممکن است نشاندهنده یک خطا باشند.
-
- برخی از دادههای پرت صحیح هستند و نشاندهنده ناهنجاریهای واقعی هستند؛ این دادهها نباید حذف یا اصلاح شوند.
- برخی از دادههای پرت نشاندهنده مشکلاتی در پاکیزگی دادهها هستند، مانند حقوق ۵۰ دلار به جای ۵۰۰۰۰ دلار، زیرا به جای ویرگول، یک نقطه تایپ شده است.
انواع دادهها در Tableau
پایگاههای داده، برخلاف صفحات گسترده، معمولاً قوانین سختگیرانهای را در مورد انواع دادهها اعمال میکنند. انواع دادهها، دادهها را در یک فیلد مشخص طبقهبندی میکنند و اطلاعاتی در مورد نحوه قالببندی، تفسیر دادهها و عملیاتی که میتوان روی آن دادهها انجام داد، ارائه میدهند. به عنوان مثال، فیلدهای عددی میتوانند عملیات ریاضی روی آنها اعمال شود و فیلدهای جغرافیایی میتوانند نقشهبرداری شوند.
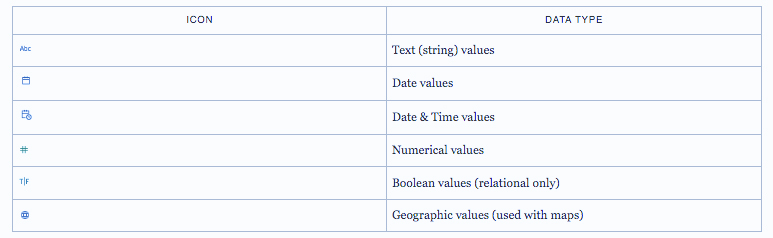
Tableau Desktop مشخص میکند که آیا یک فیلد بُعد است یا معیار، اما فیلدها ویژگیهای دیگری دارند که به نوع داده آنها بستگی دارد. این ویژگیها با آیکونی که هر فیلد دارد نشان داده میشوند (اگرچه برخی از انواع یک آیکون مشترک دارند). Tableau Prep از انواع داده مشابهی استفاده میکند. اگر نوع داده روی یک ستون اعمال شود و یک مقدار موجود با نوع داده اختصاص داده شده به آن مطابقت نداشته باشد، ممکن است به صورت تهی نمایش داده شود (زیرا “بنفش” به معنای هیچ عددی نیست).
برخی از توابع به انواع داده خاصی نیاز دارند. به عنوان مثال، نمیتوانید از CONTAINS با یک فیلد عددی استفاده کنید. توابع نوع برای تغییر نوع داده یک فیلد استفاده میشوند. به عنوان مثال، DATEPARSE میتواند یک تاریخ متنی را با فرمت خاصی بگیرد و آن را به یک تاریخ تبدیل کند، بنابراین مواردی مانند حفاری خودکار در نما را فعال میکند.
دادههای Pivot و Unpivot
دادههای کاربرپسند اغلب در قالبی عریض با ستونهای زیاد ثبت و ضبط میشوند. همچنین دادههای قابل خواندن توسط ماشین، مانند آنچه Tableau ترجیح میدهد، در قالبی بلند با ستونهای کمتر و ردیفهای بیشتر بهتر هستند.
توجه: به طور سنتی، چرخش دادهها به معنای رفتن از ارتفاع بلند به عرض (ردیفها به ستونها) است و unpivot به معنای رفتن از عرض به ارتفاع بلند (ستونها به ردیفها) است. با این حال، Tableau از کلمه pivot به معنای رفتن از عرض (کاربرپسند) به ارتفاع بلند (قابل خواندن توسط ماشین) با تبدیل ستونها به ردیفها استفاده میکند. در این سند، pivot به معنای Tableau از کلمه اشاره دارد. برای وضوح بیشتر، میتوان به مشخص کردن “محور ستونها به ردیفها” یا “محور ردیفها به ستونها” کمک کرد.
دادههای گسترده (Wide)
در مجموعه دادههای مالاریای سازمان بهداشت جهانی، یک ستون برای کشور و سپس یک ستون برای هر سال وجود دارد. هر سلول نشان دهنده تعداد موارد مالاریا برای آن کشور و سال است. در این قالب، ما 108 ردیف و 16 ستون داریم.
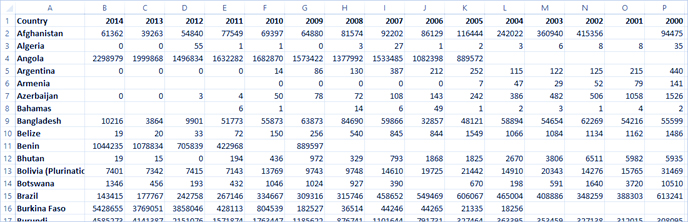
خواندن و درک این قالب برای یک فرد آسان است. با این حال، اگر این دادهها را به Tableau Desktop بیاوریم، برای هر ستون یک فیلد دریافت میکنیم. یک فیلد برای سال ۲۰۰۰، یک فیلد برای سال ۲۰۰۱، یک فیلد برای سال ۲۰۰۲ و غیره داریم.
به عبارت دیگر، ۱۵ فیلد وجود دارد که همگی نشاندهنده یک چیز اساسی هستند – تعداد موارد گزارششده مالاریا – و هیچ فیلد واحدی برای زمان وجود ندارد. این امر تجزیه و تحلیل دادهها را در طول زمان بسیار دشوار میکند زیرا دادهها در فیلدهای جداگانه ذخیره میشوند.
نشانه دیگری که نشان میدهد این قالب برای تحلیل ایدهآل نیست، این است که هیچ جا اطلاعاتی در مورد معنای واقعی مقادیر نداریم. برای الجزایر در سال ۲۰۱۲، مقدار ۵۵ را داریم. پنجاه و پنج چی؟ از ساختار دادهها مشخص نیست.
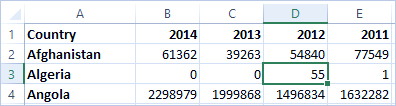
اگر نام ستون، مقادیر را توصیف نمیکند، بلکه اطلاعات اضافی را منتقل میکند، این نشانهای است که دادهها باید تغییر شکل داده شوند.
دادههای بلند (Tall)
اگر دادهها را تغییر شکل دهیم، دادهها را از حالت گسترده به بلند تغییر شکل میدهیم. اکنون، به جای داشتن یک ستون برای هر سال، یک ستون واحد به نام سال و یک ستون جدید به نام موارد گزارش شده داریم. در این قالب، ۱۶۰۶ ردیف و ۳ ستون داریم. این قالب داده بلندتر است، نه پهنتر.
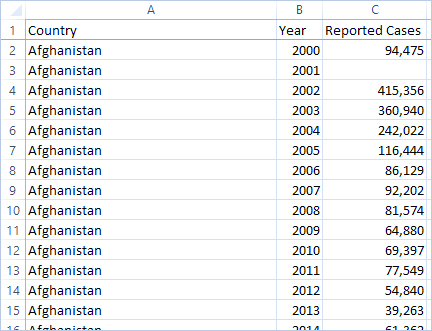
اکنون در Tableau Desktop، علاوه بر فیلد اصلی کشور، یک فیلد برای سال و یک فیلد برای موارد گزارش شده داریم. انجام تجزیه و تحلیل بسیار آسانتر است زیرا هر فیلد نشان دهنده یک کیفیت منحصر به فرد در مورد مجموعه دادهها – مکان، زمان و ارزش – است.
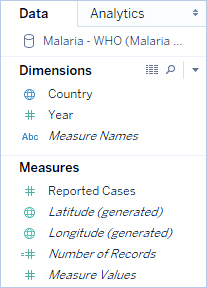
توجه: این تصویر برای نمایش جدیدترین رابط کاربری بهروزرسانی نشده است. پنجره دادهها دیگر ابعاد و اندازهگیریها را به عنوان برچسب نشان نمیدهد.
اکنون به راحتی میتوان دید که برای الجزایر در سال ۲۰۱۲، عدد ۵۵ به تعداد موارد گزارششده اشاره دارد (زیرا میتوانیم این ستون جدید را برچسبگذاری کنیم).
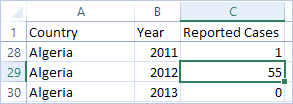
در این مثال، دادههای عریض شامل یک رکورد واحد برای هر کشور بود. با فرمت دادههای بلند، اکنون ۱۵ ردیف برای هر کشور وجود دارد (یکی برای هر ۱۵ سال در دادهها). مهم است به خاطر داشته باشید که اکنون چندین ردیف برای هر کشور وجود دارد.
اگر ستونی برای مساحت زمین وجود داشته باشد، آن مقدار برای هر ۱۵ ردیف برای هر کشور در یک ساختار داده بلند تکرار میشود. اگر با بیرون آوردن کشور به ردیفها و مساحت زمین به ستونها، یک نمودار میلهای ایجاد کنید، به طور پیشفرض، نما، مساحت زمین را برای هر ۱۵ ردیف برای هر کشور جمع میکند.
برای برخی از فیلدها، ممکن است لازم باشد مقادیر شمارش دوگانه را با تجمیع با میانگین یا حداقل به جای جمع یا فیلتر کردن جبران کنید.
نرمالسازی (Normalization)
پایگاههای داده رابطهای از چندین جدول تشکیل شدهاند که میتوانند به نحوی با هم مرتبط یا پیوند داده شوند. هر جدول شامل یک شناسه منحصر به فرد یا کلید برای هر رکورد است. با مرتبط کردن یا اتصال کلیدها، رکوردها میتوانند به هم پیوند داده شوند تا اطلاعات بیشتری نسبت به آنچه در یک جدول واحد موجود است، ارائه دهند. اینکه چه اطلاعاتی در هر جدول قرار میگیرد به مدل داده مورد استفاده بستگی دارد، اما اصل کلی حول محور کاهش تکرار است.
به عنوان مثال، برنامهریزی رویدادی مانند عروسی را در نظر بگیرید. ما باید اطلاعات را در سطح گروهها (مانند خانوادهها یا زوجها) و همچنین در سطح افراد پیگیری کنیم.
میتوان جدولی ایجاد کرد که تمام اطلاعات را با هم ترکیب کند:
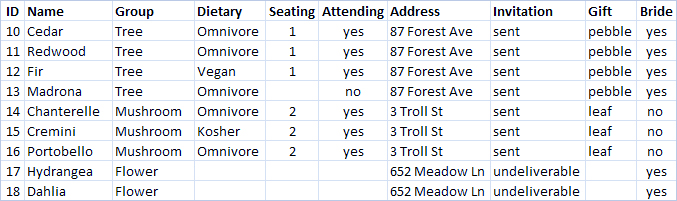
با این حال، اگر آدرسی نادرست باشد و نیاز به اصلاح داشته باشد، باید در چندین ردیف اصلاح شود که به طور بالقوه منجر به خطا یا تداخل میشود. ساختار بهتر این است که دو جدول ایجاد شود، یکی برای اطلاعات مربوط به گروه (مانند آدرس و اینکه آیا دعوتنامه ارسال شده است یا خیر) و دیگری برای اطلاعات مربوط به افراد (برای مواردی مانند تعیین محل نشستن و محدودیتهای غذایی).
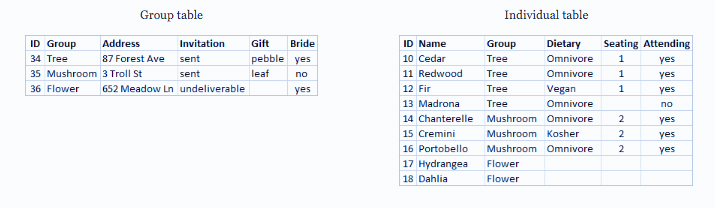
ردیابی و تحلیل اطلاعات سطح گروه در جدول گروهی و اطلاعات سطح فرد در جدول فردی بسیار آسانتر است. به عنوان مثال، تعداد صندلیهای مورد نیاز را میتوان از تعداد رکوردهای Attending = Yes در جدول فردی به دست آورد و تعداد تمبرهای مورد نیاز برای تشکر را میتوان از تعداد رکوردهای جدول گروهی که Gift در آنها null نیست، به دست آورد.
Structure Data
فرآیند تجزیه تمام دادهها به چندین جدول – و تشخیص اینکه کدام جدول شامل کدام ستونها است – نرمالسازی نامیده میشود. نرمالسازی به کاهش دادههای اضافی کمک میکند و سازماندهی پایگاه داده را ساده میکند.
با این حال، ممکن است مواقعی وجود داشته باشد که به اطلاعاتی نیاز باشد که چندین جدول را در بر بگیرد. به عنوان مثال، اگر بخواهیم چیدمان صندلیها (افراد) را به گونهای متعادل کنیم که گروههای طرف عروس با گروههای طرف داماد در هم آمیخته شوند، چه؟ (وابستگی پل یا داماد در سطح گروه ردیابی میشود.) برای دستیابی به این هدف، باید جداول را دوباره به هم مرتبط کنیم تا افراد با اطلاعات مربوط به گروه خود مرتبط شوند.
نرمالسازی صحیح فقط به تقسیم جداول خلاصه نمیشود، بلکه به وجود یک فیلد مشترک و مرتبط یا شناسه منحصر به فرد نیز نیاز دارد که بتوان از آن برای ترکیب مجدد دادهها استفاده کرد. در اینجا، آن فیلد مرتبط، گروه (Group) است. آن فیلد در هر دو جدول وجود دارد، بنابراین میتوانیم در این فیلد به هم متصل شویم و به قالب اصلی و واحد جدول خود برگردیم. این یک ساختار غیرنرمالسازی شده (denormalized) است.
پس چرا جدول اصلی غیرنرمالسازی شده را نگه نداشتیم؟ نگهداری آن دشوارتر است و اطلاعات اضافی را ذخیره میکرد. در مقیاس بزرگ، سطح تکثیر دادهها میتواند بسیار زیاد شود. ذخیره مکرر اطلاعات یکسان کارآمد نیست.
جداول نرمالسازی شده چند ویژگی کلیدی دارند:
- هر سطر به یک شناسه منحصر به فرد نیاز دارد
- هر جدول به یک یا چند ستون نیاز دارد که بتوان از آنها برای اتصال مجدد آن به جداول دیگر (کلید) استفاده کرد.
این ستونهای مشترک (کلید) برای ارتباط یا اتصال مجدد جداول به یکدیگر استفاده میشوند. برای دادههای ما، عبارت relationship یا join در فیلد Group در هر جدول قرار خواهد گرفت.
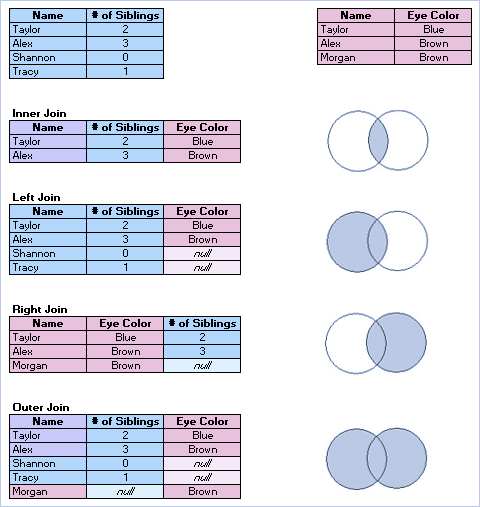
انواع پیوند (Join)
اگرچه روش پیشفرض برای ترکیب دادهها در Tableau Desktop، مرتبط کردن است، مواردی وجود دارد که ممکن است بخواهید جداول را در Tableau Desktop یا Tableau Prep Builder به هم پیوند دهید.
برای خرید لایسنس نرم افزار Tableau ، میتوانید از خدمات ما استفاده نموده و درخواست خود را از طریق فرم زیر ثبت نمایید.



{kind=link}
بدون دیدگاه